
In this blog, we will explore how to implement Pagination in Azure Data Factory (ADF) for making REST API calls and efficiently storing the retrieved data. Pagination is a crucial technique for handling large datasets, allowing us to retrieve data in smaller chunks to optimize performance and reduce resource consumption.
Architecture:
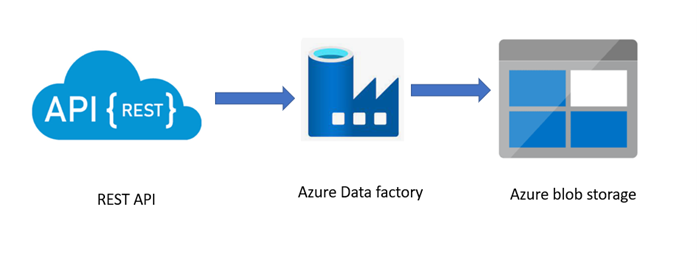
Azure data factory:
- Azure Data Factory is a Cloud-based ETL tool useful for performing data integration for automation and transformation of data
- We can create data integration solutions using a Data Factory to ingest data from different sources, transform it, publish and store it into diverse datasets
- Data Factory can consume data from both on-premises and cloud.
Blob storage:
Blob storage is a type of cloud storage for unstructured data. A Blob is used to store the data.
Step1:
- Go to Azure Data Factory
- Next, take to ‘activities’
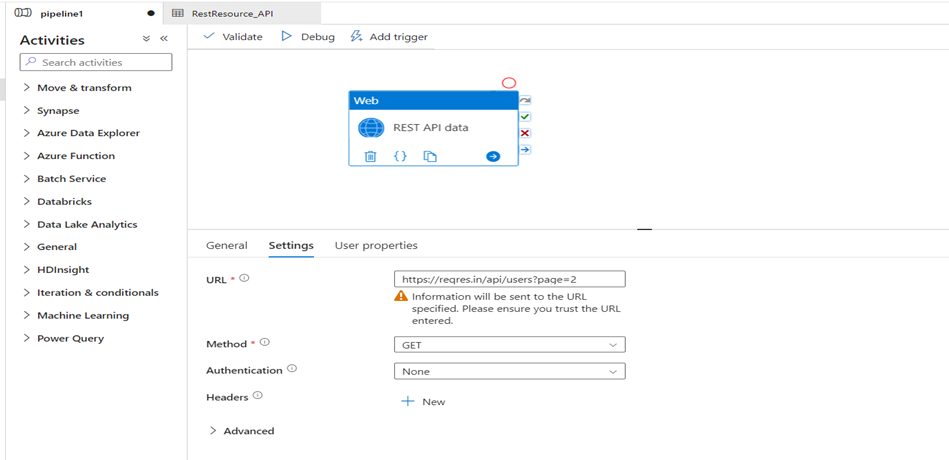
- Go to ‘setting’ and give the URL in which you want to do the pagination of data
- Select the GET method for that URL
- GET method is used to retrieve the information about the REST API Resource
Step2:
- Go to the ’Foreach’ activity, then connect to the web. ‘Foreach’ activity is used to repeat the control flow
- ‘Foreach’ activity is used to iterate the specified activities in a loop. The range of the REST API can be given
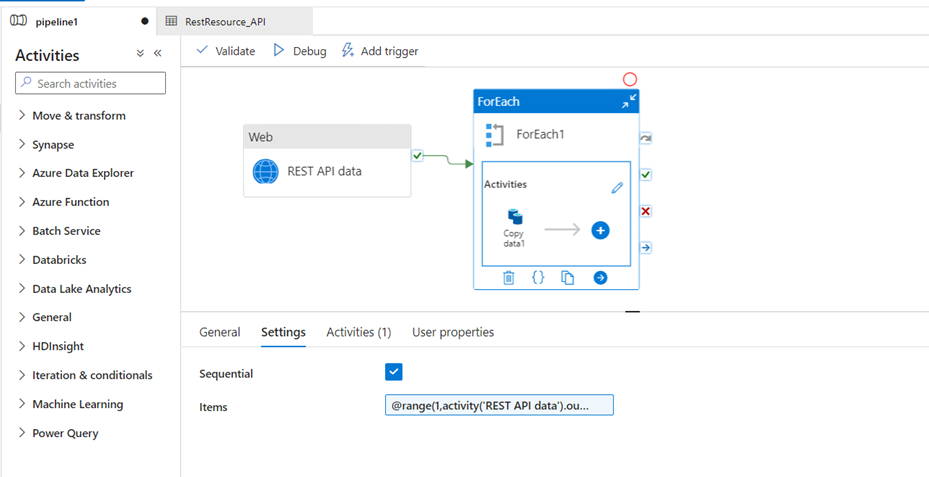
Step 3:
- In the ‘foreach’ activity, we may take one copy activity to load the data from REST API to Blob storage
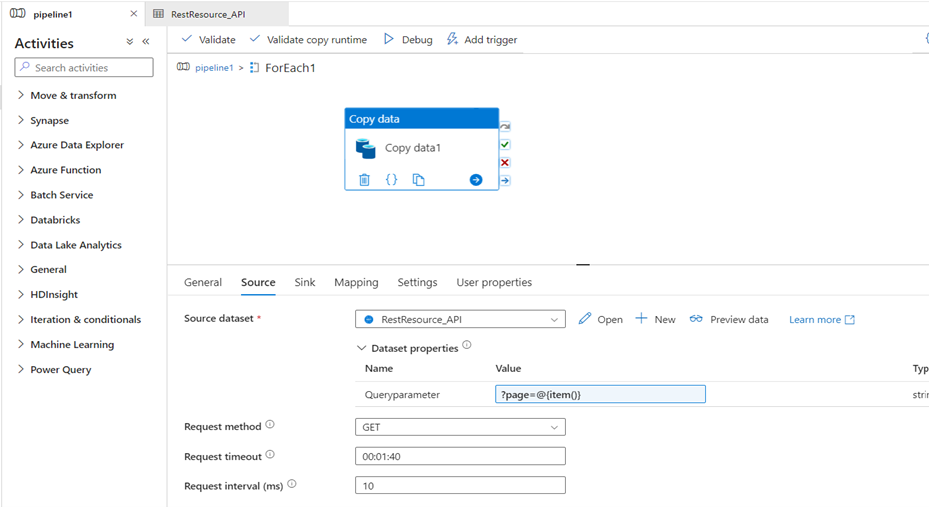
- In source, we need to make REST API as the source. In that, we need to create a dataset. In that data set we must create a linked service with the required details like Base URL and authentication type
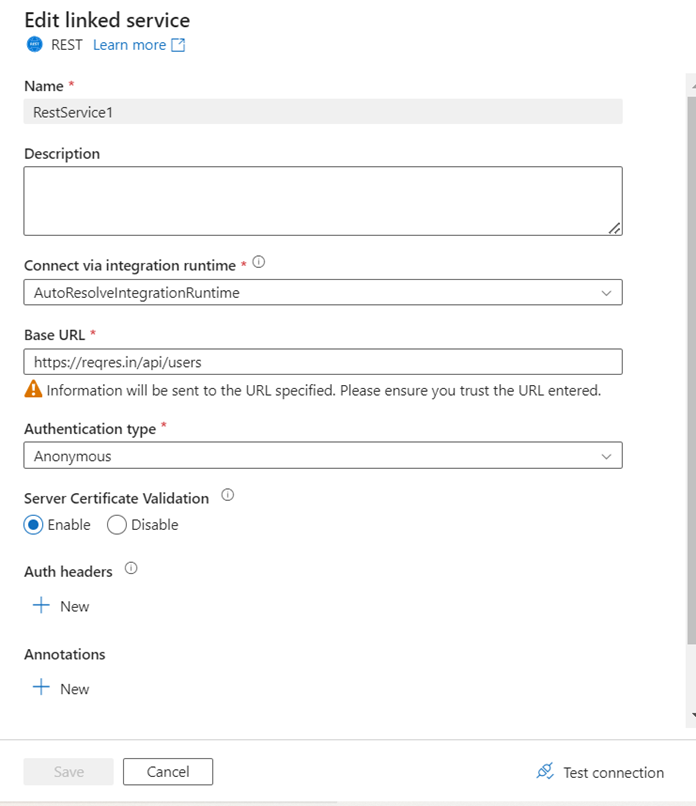
- It is time to test the connection
- Next, go to source, then go to parameters.Now, give the parameter, a name
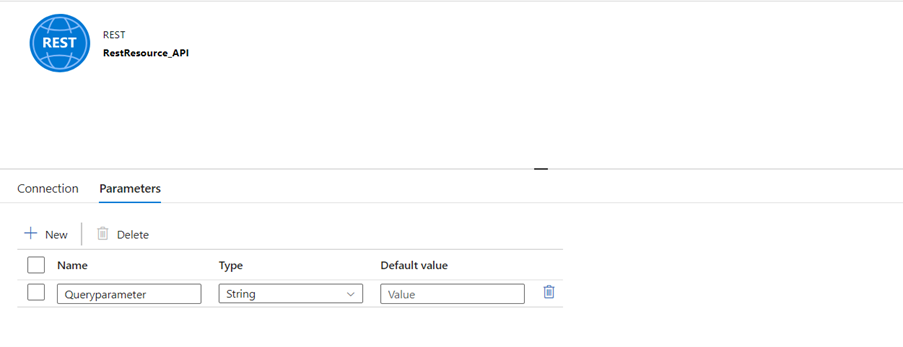
- Click on the connection. Give the parameter a name on the Relative URL
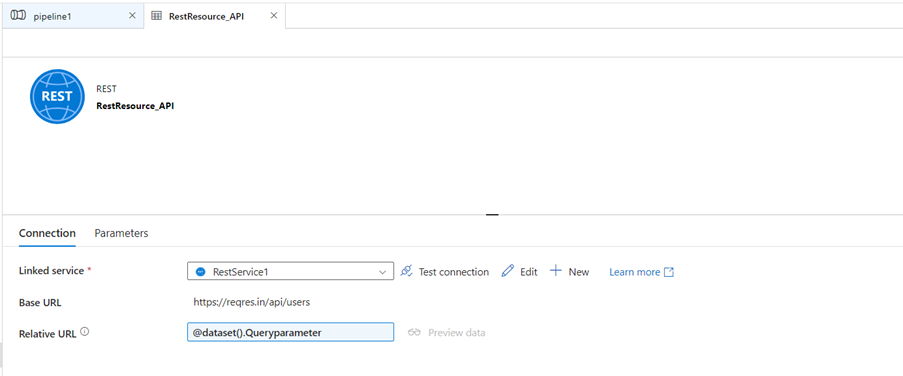
- Then go to the pipeline
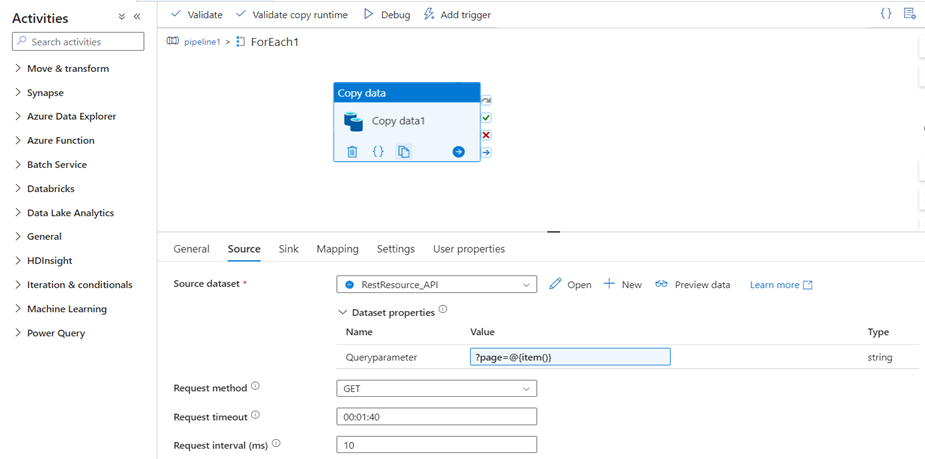
- In the dataset properties, you can give a value to the parameter. The value given is based on the Pagination of the API
Step 4:
- In the sink we need to create the storage account to load the data from API
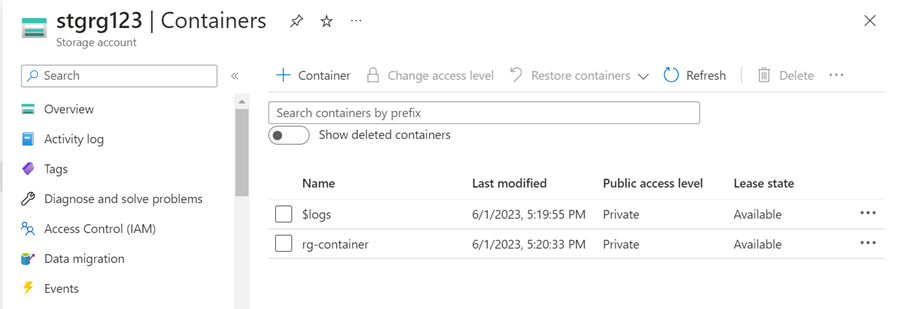
- Storage account is created
- For the sink side, we need to create the linked service with the required details
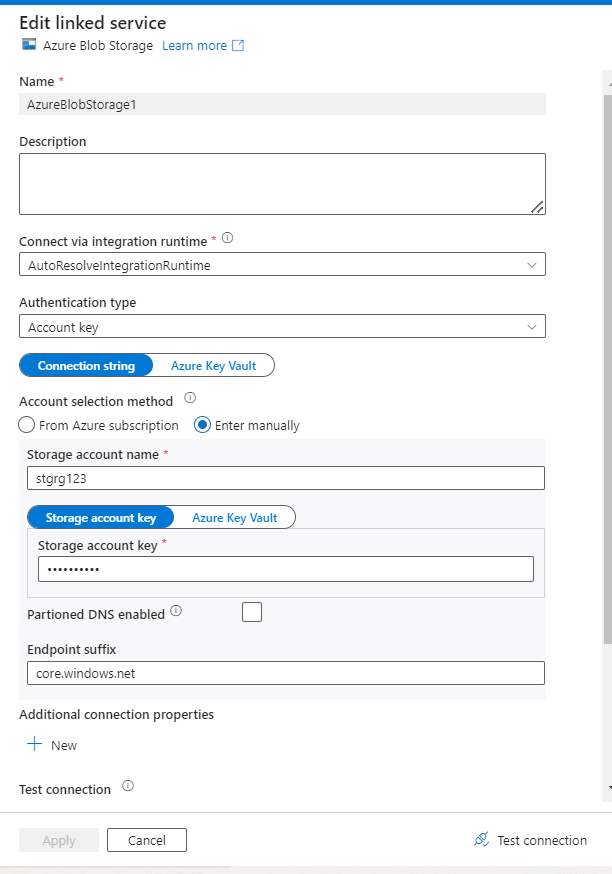
- It is time to test the connection
- Go to the parameters in the sink. Give the parameter, a name
- Go to connection and give the file path in which path we need to load the data
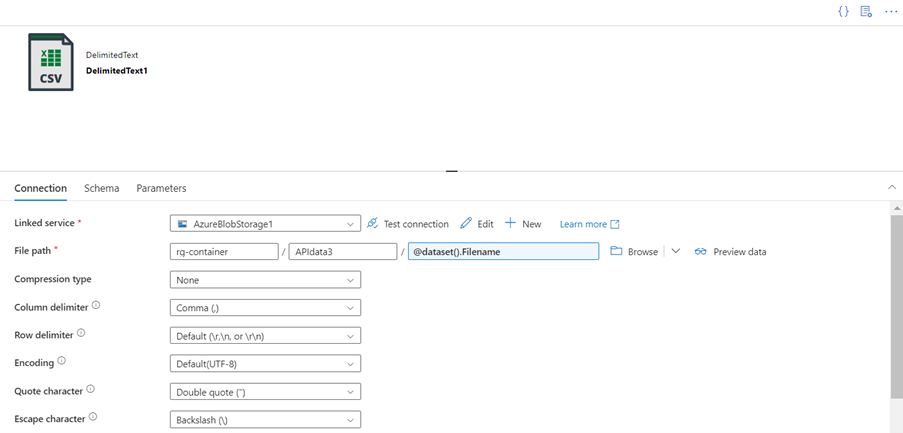
- In the file path, we give the file name by using a parameter
- Let the parameter automatically create the file name
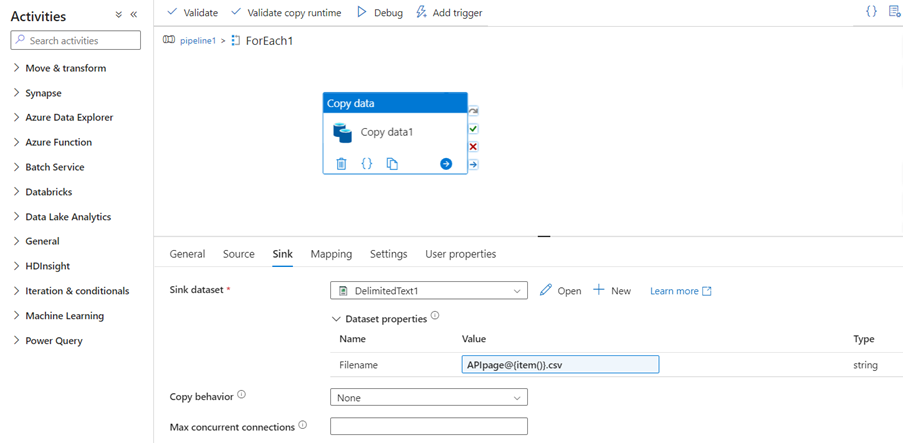
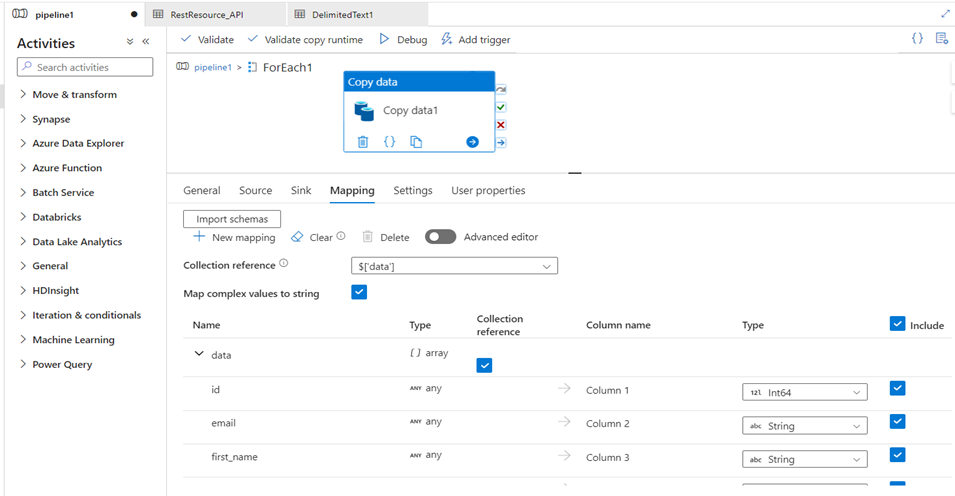
- Navigate to the map and load the desired data
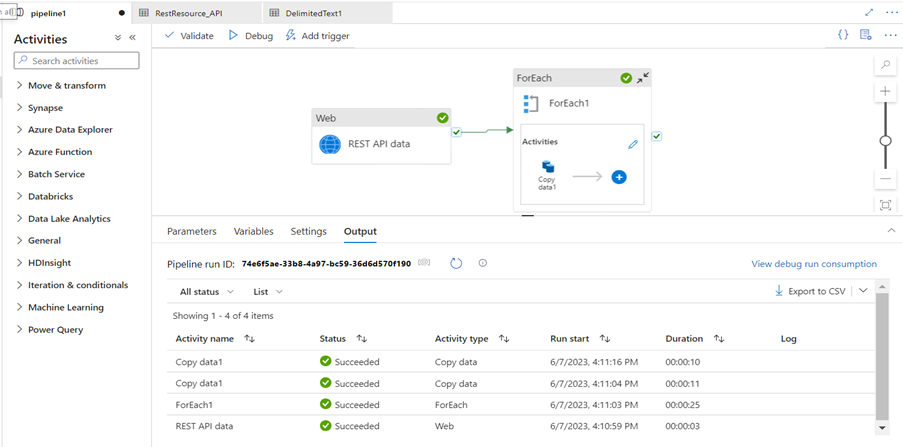
- Validate the pipeline. If there are no errors, debug it
- Go to the Storage account and check if the data loaded
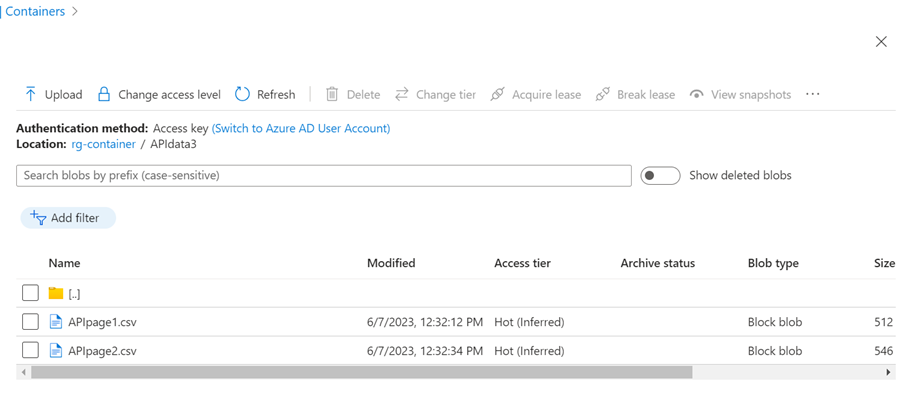
- Mostly, the data would be loaded successfully. In REST API, for two pages of data, each page is loaded in two different files
Conclusion:
By implementing this process in the Azure Data Factory, you can efficiently handle pagination for REST API calls and store the retrieved data in a scalable and organized manner. This approach enables data efficiency and provides resiliency during the pagination process. With the power of the Azure data factory, you can build robust data integration pipelines that seamlessly handle pagination for various APIs and achieve optimal performance.

