
ADF SAP CDC Connector: Optimization Techniques
There are three types of partitions in Azure CDC Connector for SAP.
- Use Current Partitioning
- Single Partition
- Set Partitioning
Here is the Azure dataflow with SAP CDC connector. The source and sink are configured as mentioned below.
This dataflow loads data, full data load on the first run, then incremental load on the second run onwards.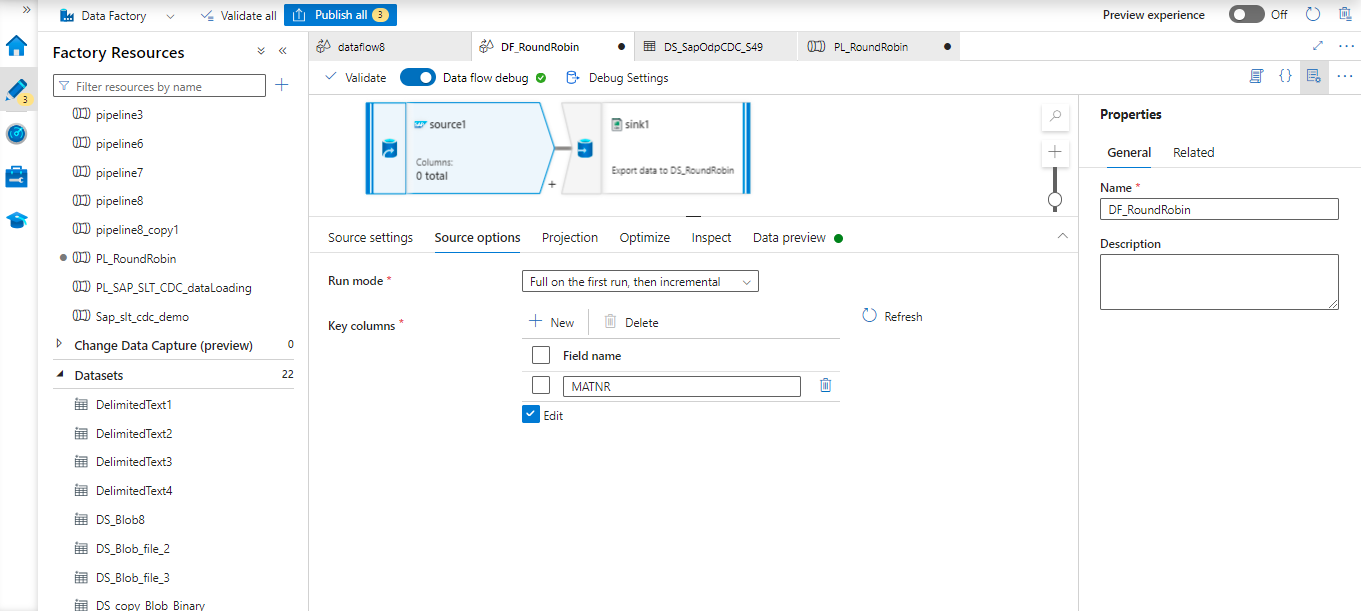
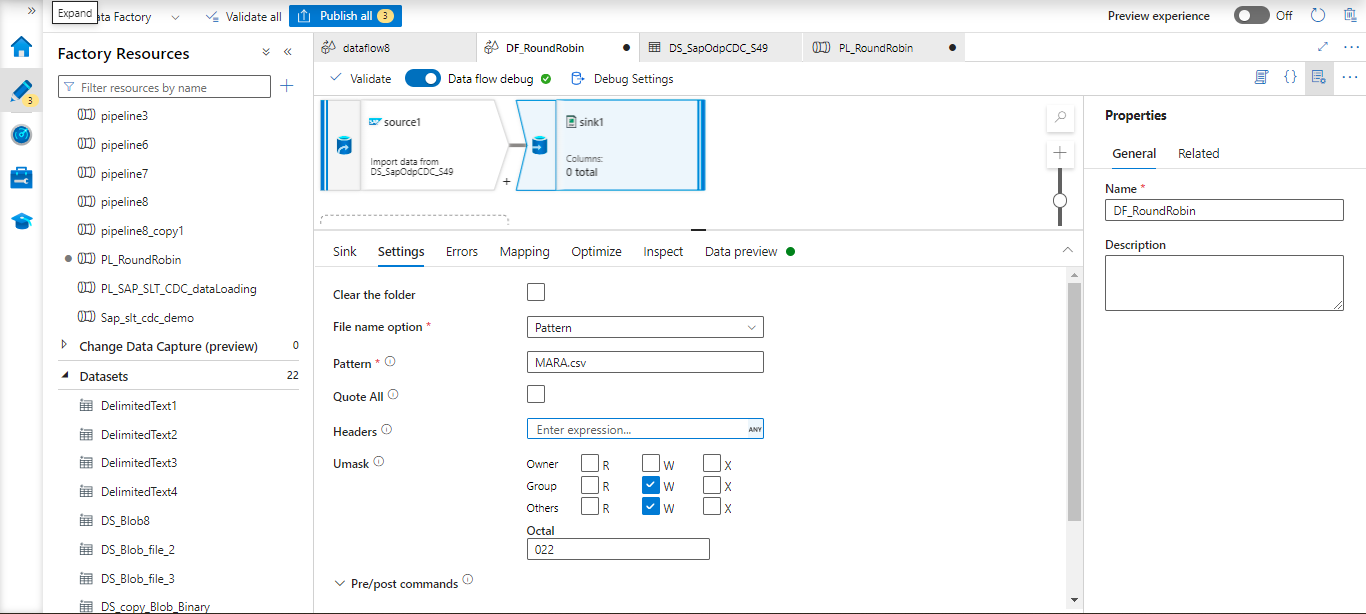
Related ODP connection has been provided and ODP name has been given in details in the source connection. Sink related configuration has been mentioned below.
Every data flow transformation contains a tab that asks whether you want to partition the data when the transformation is finished. The Spark cluster’s partitioning scheme can be configured using the parameters on the Optimize tab. Changing the partitioning gives you control over how your data is distributed among compute nodes and enables data locality optimizations, both of which can improve or degrade the speed of your data flow as a whole.
- Use Current Partitioning:
By default, as repartitioning data takes time, the use of current partitioning is recommended in most scenarios. When utilizing current partitioning is chosen, the service is instructed to maintain the transformation’s existing output partitioning.
- Single Partition:
This option is strongly discouraged unless there is an explicit business reason to use it.
All dispersed data is combined into a single partition. All subsequent transformations and writes will be greatly impacted by this prolonged operation.
- Set Partitioning
Other than the previous partition types, Set Partitioning has multiple partition types.
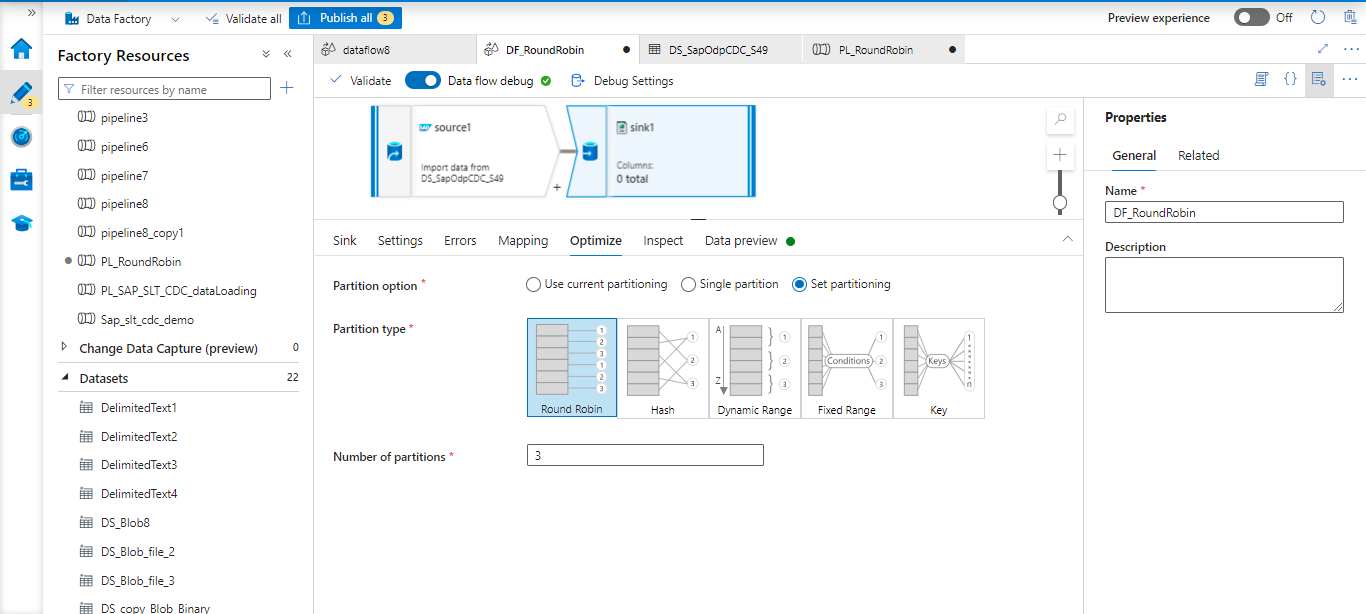
Round Robin
Data is evenly distributed among partitions while using Round Robin. When you don’t have good key candidates, use this method to put a good, clever partitioning strategy into place. The number of physical partitions is programmable. Partition types are mentioned below.
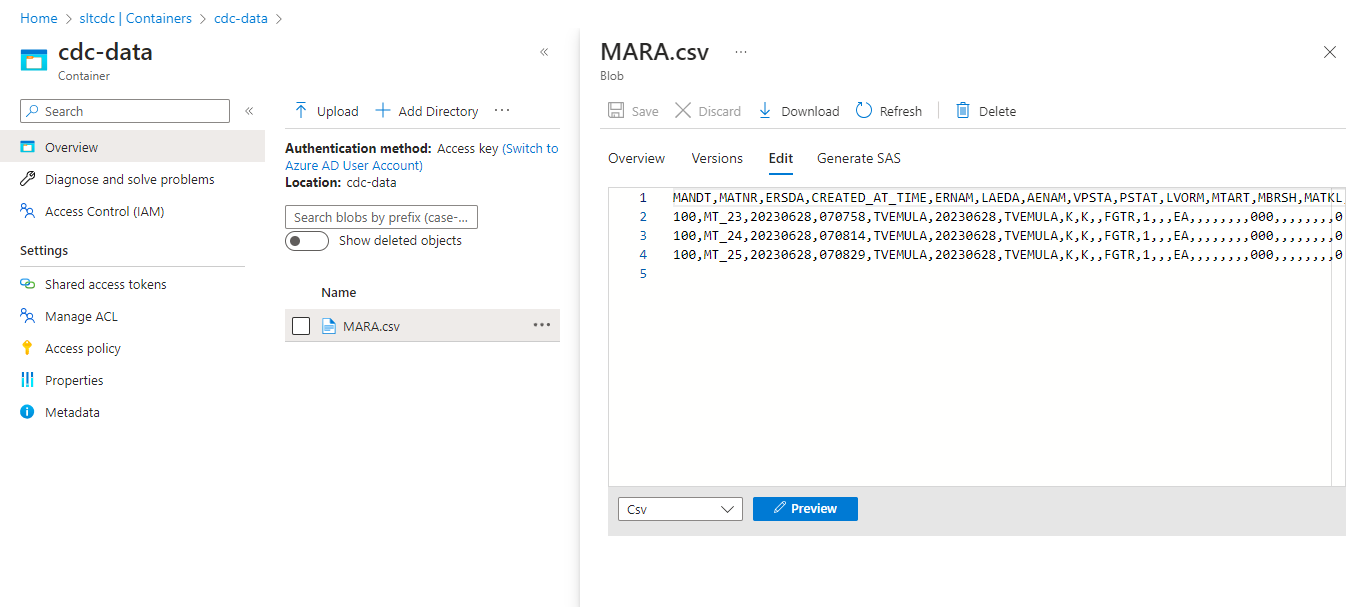
The pipeline runs successfully, and the complete data is loaded into the staging location.
We have chosen, the partition type to be Round Robin, and the number of partitions to be 3. The whole data distributes into 3 partitions.
Output of First Partition
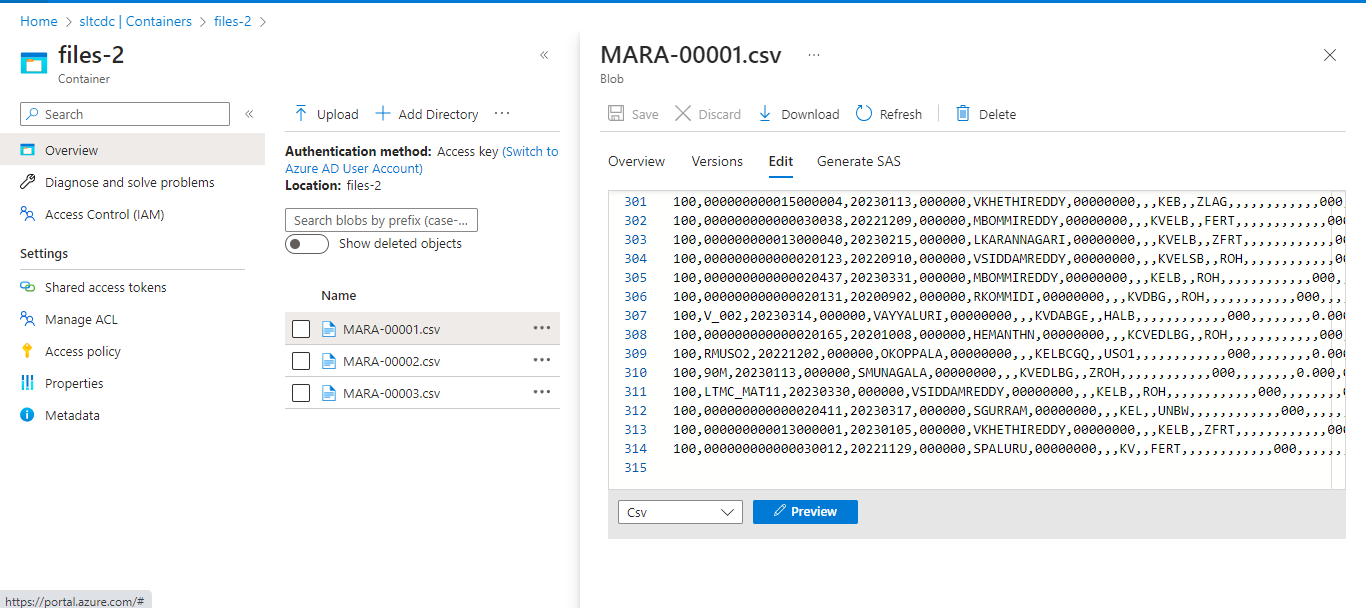
We can also see other partitioned data in the remaining files.
In the second Run, data loading in an incremental manner (it loads only newly created or updated records)
First partition output:
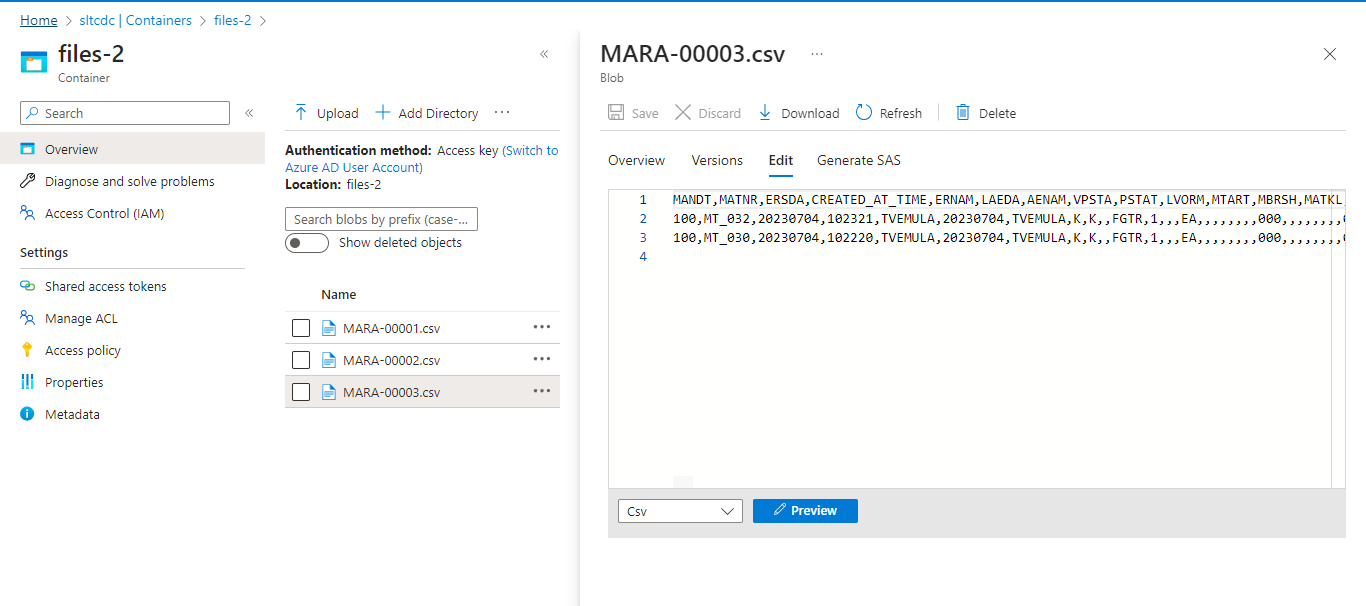
As well as we can see Second and Third partitioned output data.
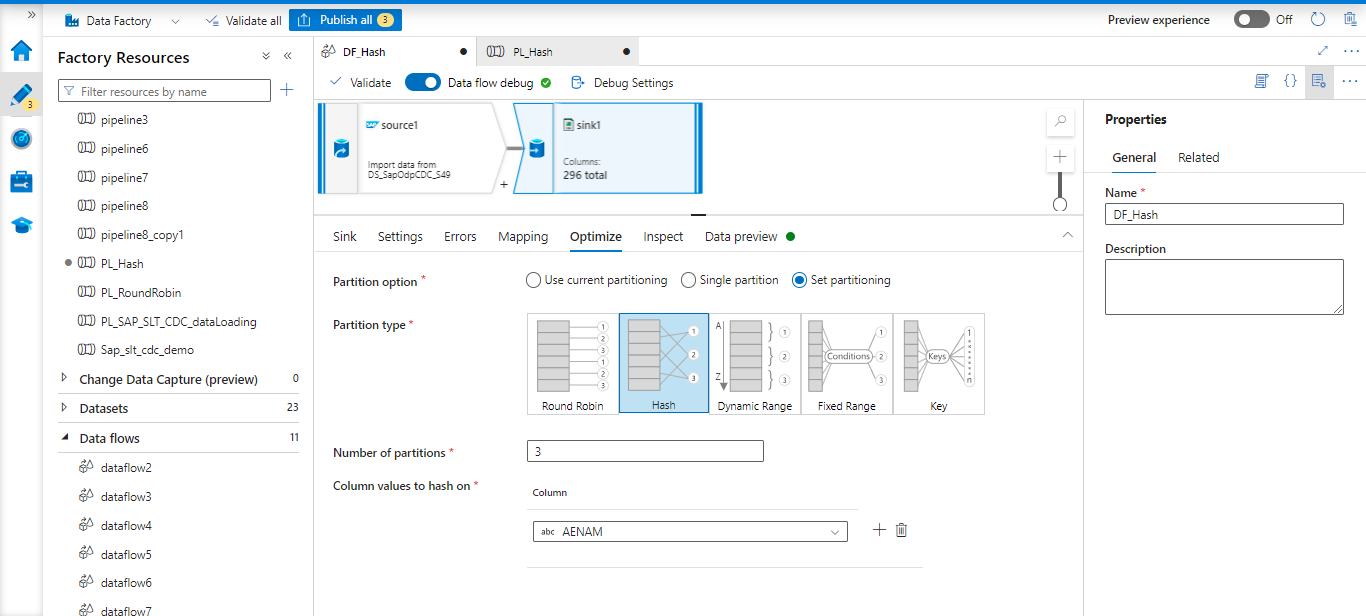
Hash
In order to create consistent partitions, the service creates a hash of the columns, ensuring that rows with identical values are placed in the same partition. You can set the number of physical partitions.
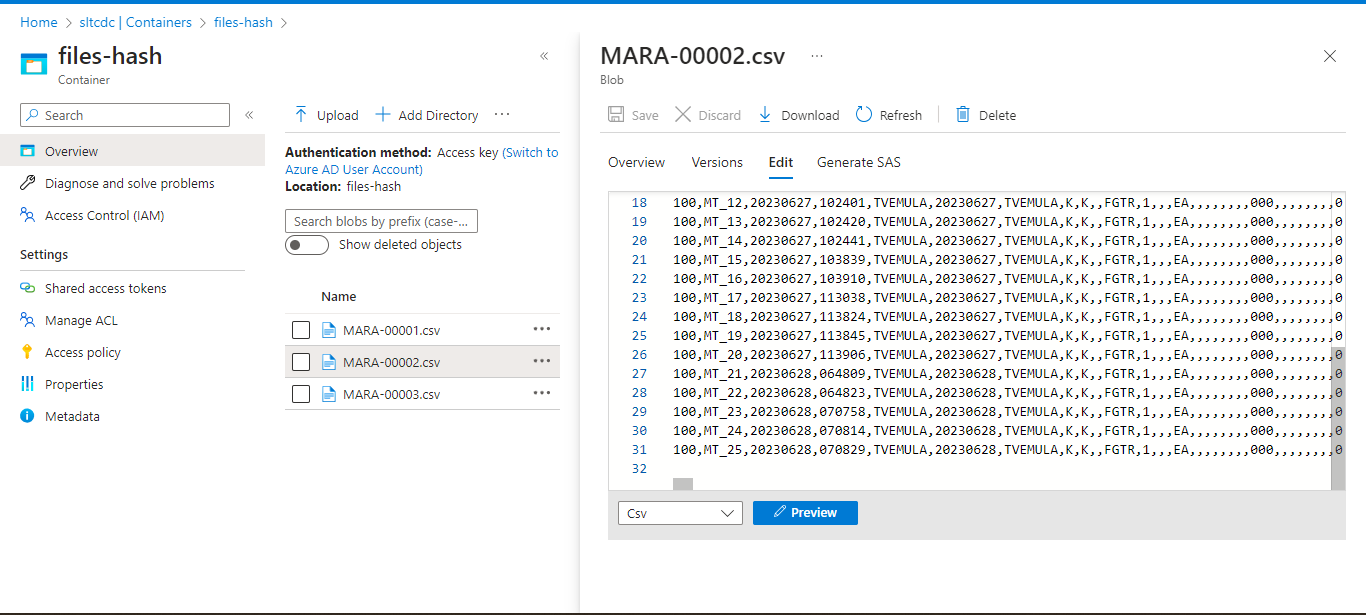
Here choose the Hash Partition type and column name username (who creates the records); based on this column name. Data will be distributed into 3 partitions.
Based on the partitions of username data splits into different files
Dynamic Range:
The dynamic range is based on the columns or expressions you supply, using Spark dynamic ranges. You can set the number of physical partitions.
We can partition the data based on columns or using expression builder condition.
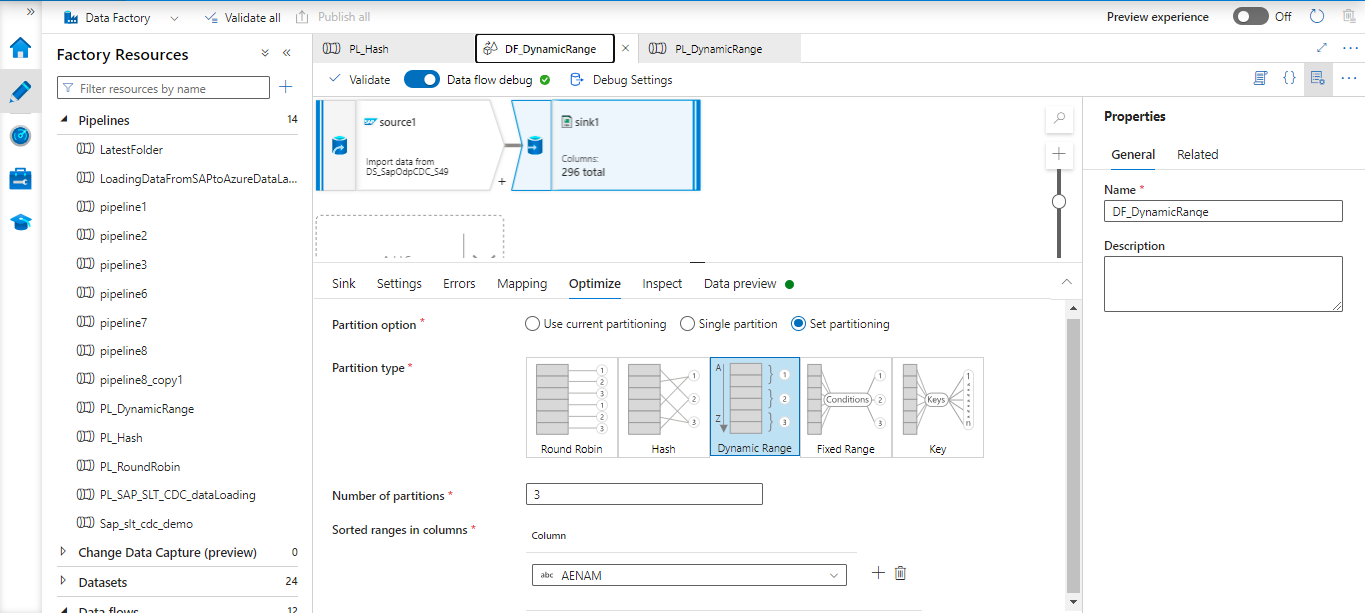
Output after pipeline run
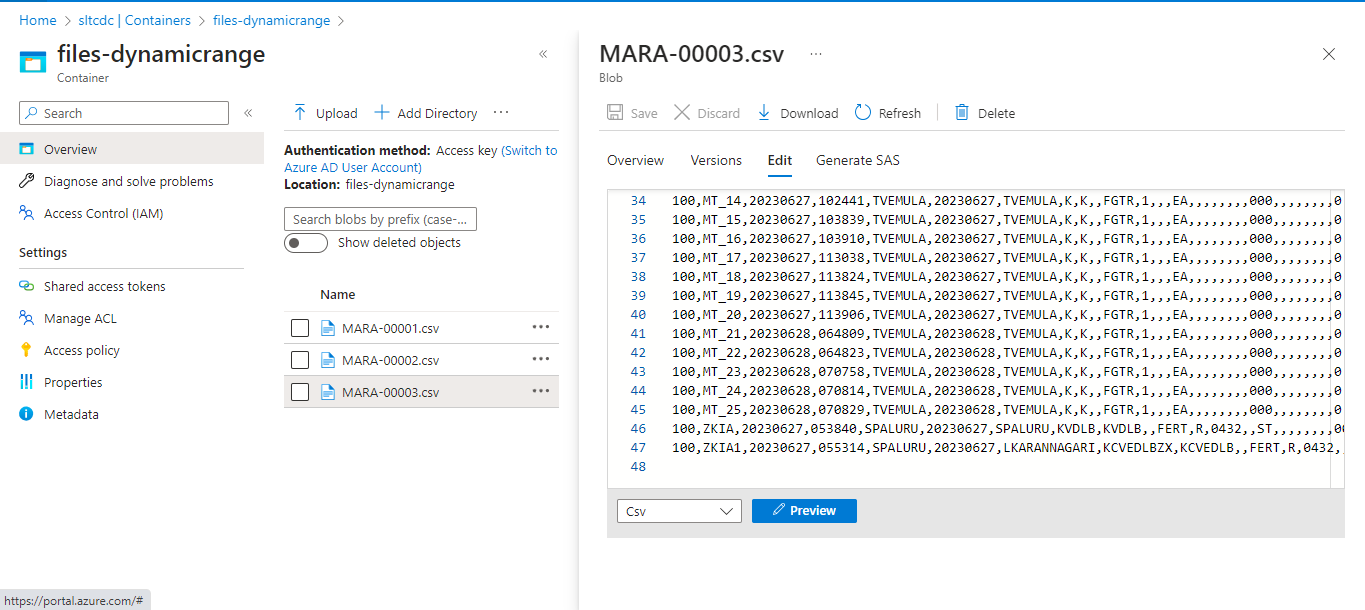
Likewise, we can also perform the below optimization techniques –
Fixed Range:
You can set the number of physical partitions. Create an expression that gives values inside the partitioned data columns a fixed range. The partition function incorporates the values you enter for the expression. Before using this option, you should have a solid understanding of your data to prevent partition skew.
Key:
You can’t set the number of partitions because the number is based on unique values in the data. Key partitioning might be a wise choice if you have a solid understanding of the cardinality of your data. For each distinct value in your column, key partitioning creates its own partition.
References:
https://www.vizeit.com/performance-optimization-in-azure-data-factory/
https://dev.to/swatibabber/adf-mapping-data-flows-performance-and-tuning-51pp
https://learn.microsoft.com/en-us/azure/data-factory/concepts-data-flow-performance

