
Purpose of the article: : In this blog, we have explained how to implement governance using LAKE FORMATION on data lake to different users based on set of rules.
Intended Audience: This blog will assist you in implementing SECURITY and GOVERNANCE on.
Tools and Technology: AWS Services (S3, Lake Formation, IAM, Glue)
Keywords: Lake Formation
Introduction:
LAKE-FORMATION (LF) is a comprehensive data management and governance service provided by AWS. It simplifies the process of building, securing, and managing data lakes, which are centralized repositories that allow organizations to store all their structured and unstructured data at any scale.
Demonstrated here are the LF capabilities and offerings to provide secure and controlled access for the DATA LAKE solution.
Architecture:
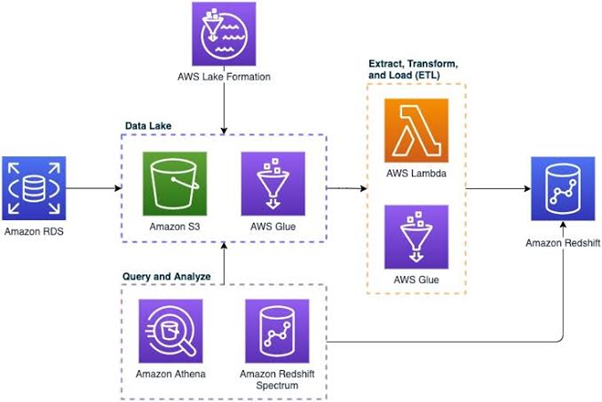
Components:
- Data Ingestion: The process enables users to ingest data from various sources, including databases, data streams, logs, and more. It supports diverse data formats and allows seamless data integration into the Data Lake.
- Cataloging: The service organizes and catalogs data using a central metadata catalog. This catalog helps discover, understand, and manage the lake’s data. It provides a unified view of the metadata, making searching and accessing data easier.
- Security: The service also incorporates robust security features. It allows users to set fine-grained access controls and define permissions at different levels, ensuring data privacy and compliance with regulations. This includes managing access using AWS IAM policies.
- Governance & Compliance: Offers tools for data governance, enabling organizations to set up policies for data access, managing data retention, and complying with regulatory requirements. It helps in tracking data lineage and maintaining audit trails.
Functionality:
- Automates the setup of Data Lakes, reducing the complexities involved in the process and allowing users to set up a secure, scalable Data Lake environment more efficiently.
- Provides a centralized platform for managing and governing data. Easy to monitor data access, apply security controls, and manage data permissions from a unified interface.
- Designed to handle large volumes of data, with flexibility to scale according to an organization’s evolving needs. Equipped to ensure high performance in managing, processing, and analyzing data.
- Equipped to integrate seamlessly with various AWS services such as Glue, S3, Redshift etc, providing a comprehensive data management ecosystem.
- Ability to optimize costs, by leveraging a serverless architecture and pay-as-you-go pricing model, allowing businesses to pay only for the resources they consume.
Use Case: This example will help set up LF (for IAM users) having different permissions on same data set.
A user, when trying to query the data using ATHENA, can see only the data for which he has permission (column level permission), whereas others will see only the data for which they have permission.
Prerequisites:
- Create 2 IAM users with permissions to S3, Glue Data Catalog, and Crawlers, Athena (running SQL), IAM (roles and policies), and Cloudwatch access
- Create 2 IAM roles for GLUE service to access S3 and LF and for LF to connect to S3 and GLUE data catalogs (DB and tables)
- S3 Bucket to load the data on which you experiment with the LF setup. You can restrict the permission in IAM by limiting those to access only this bucket, which you will use for the POC.
Steps:
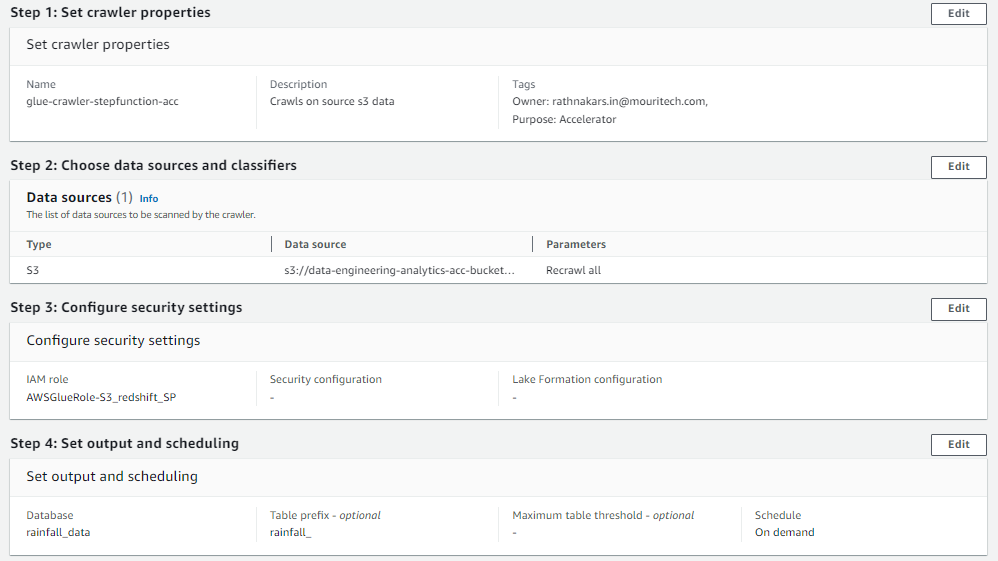
- Running of CRAWLER: Create a GLUE crawler that points to the CSV data stored in S3 (images below show a preview of a basic crawler’s appearance).
- Register a DATA LOCATION with S3 (associating the IAM role). After doing this, you will be able to control all permissions on this location using LF.

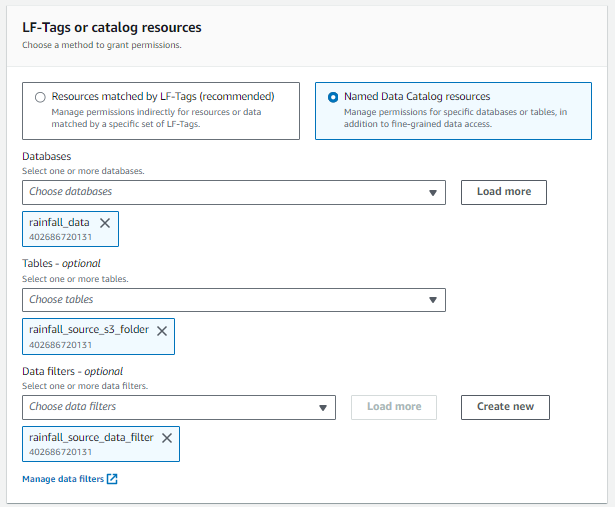
- Create the FILTERS in LF (later used for permissions)
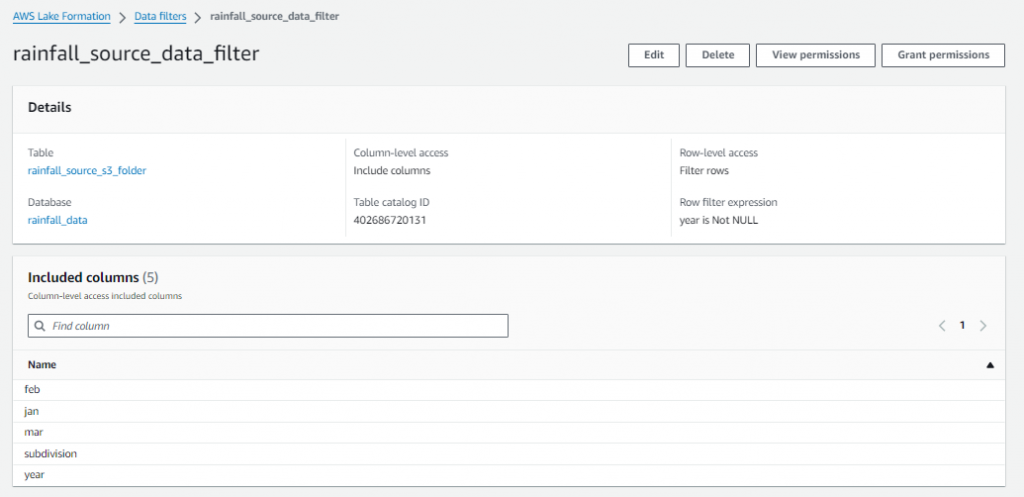
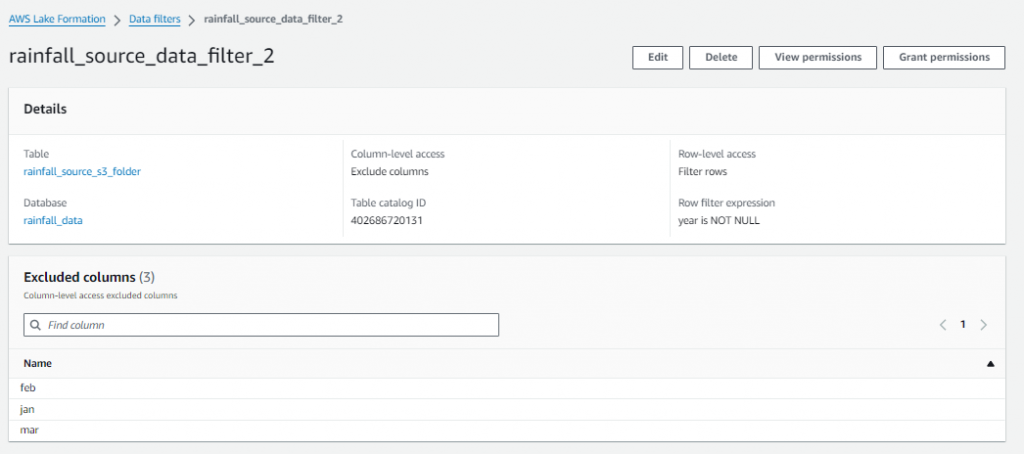
- Setup the Data Lake permissions: In this step, you apply the rules of LF for IAM users.
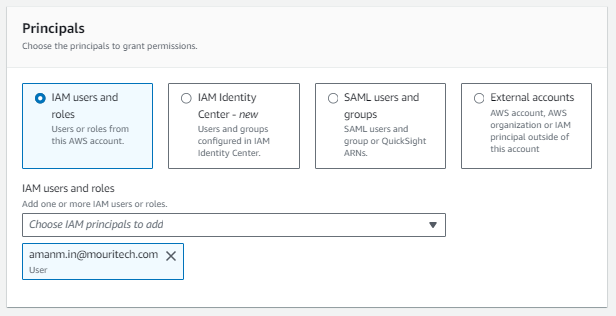
IAM USER 1:
IAM USER 2:
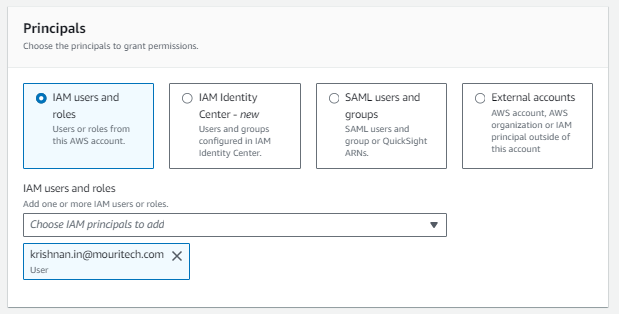
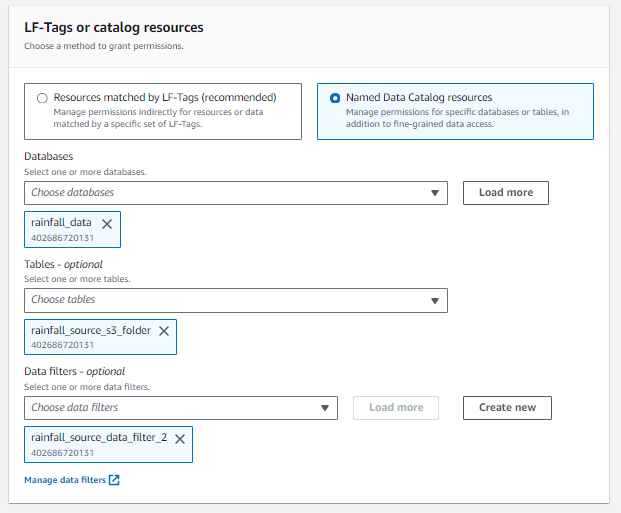
NOTE: As per the results of the above rules, when you query with different users in ATHENA console, you will see the results as per the filters selected above.
- SELECT query to run on ATHENA for IAM User 1:
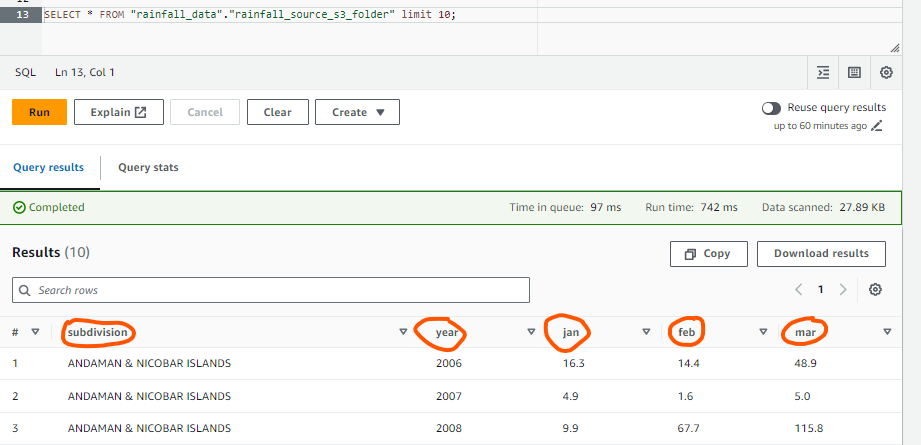
As shown, only five columns come in the output, as mentioned in FILTER 1
SELECT query to run on ATHENA for IAM User 2:
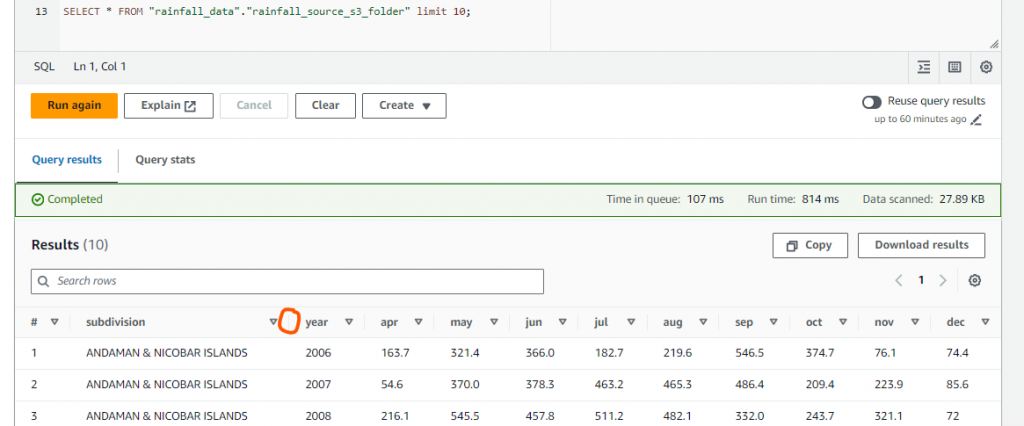
As shown above, columns excluded in FILTER 2 don’t appear.
Advantages:
- LF streamlines building a Data Lake on AWS by automating numerous tasks, such as setting up storage, defining schemas, and ingesting data from various sources.
- It enables organizations to consolidate diverse data types and formats in a single, easily accessible repository, allowing for easy storage and retrieval of structured and unstructured data.
- It integrates robust security measures, making it easier to manage data access with fine-grained access control, ensuring that only authorized users and applications can access the Data Lake.
- The service offers features to enforce governance policies and compliance regulations, ensuring that data usage adheres to pre-defined organizational guidelines and standards.
- It can reduce operational costs by streamlining the setup process and providing tools to manage and utilize data resources efficiently.
Conclusion:
LF simplifies the process of building and managing Data Lakes, making it easier for organizations to derive insights, perform analytics, and extract value from their data. By providing an integrated suite of tools for data ingestion, cataloging, security, and governance, it streamlines the management of vast amounts of data, fostering a more efficient and secure data-driven environment.
You can control access over different data sets for other users, which helps you provide a lot of security while maintaining a DATA LAKE.
References:
- AWS Lake Formation Documentation (amazon.com)
- Data Lake Governance – AWS Lake Formation Features – AWS (amazon.com)
- AWS Lake Formation Pricing – Amazon Web Services
- AWS Lake Formation — The Gatekeeper of Data in Datalake | by Eshant Sah | Medium
- AWS Data Lakes 101 | Lesson 0: Intro and Lake Formation – YouTube
Author Bio:

Aman Maheshwari
Team Lead - Data Visualization-Data Engineering Analytics
I'm Aman Maheshwari, and I've been with Mouri Tech for 2.2 years as a Team Lead in Data Engineering. Have a good working experience with Amazon Services. Building comprehensive ETL data pipelines (Infrastructure as a Service, Platform as a Service). Expertise creating and delivering container architecture on Amazon, as well as automating pipelines and expertise in Python coding language.
