
Purpose of the article: In This article explained about efficiently copy the latest and modified files from multiple folders within an AWS S3 bucket to Azure Blob Storage.
Intended Audience: This blog guides users through setting up an Azure Data Factory (ADF) pipeline to efficiently copy the latest and modified files from multiple folders within an AWS S3 bucket to Azure Blob Storage.
Tools and Technology: AWS Services (S3), Azure Services (Azure Blob Storage, ADF).
Keywords: Data Integration, Pipeline Automation, Data Migration.
Architecture
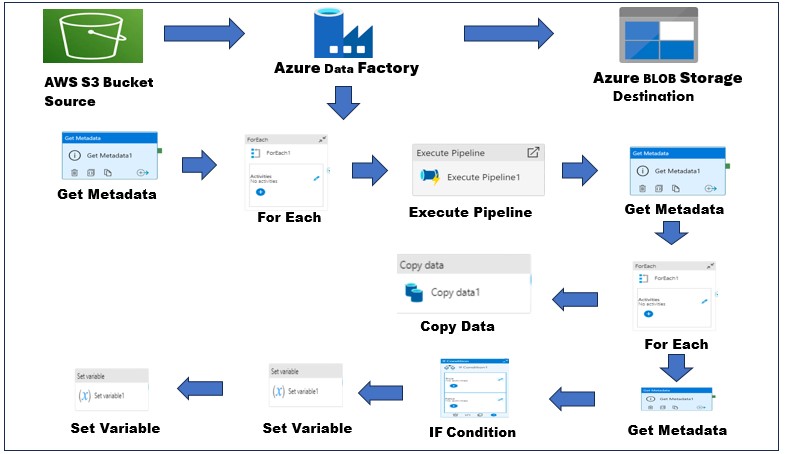
Preparatory Steps: Setting Up AWS S3, Azure Blob Storage, and ADF.
- Ensure the necessary prerequisites are in place, including setting up AWS S3, Azure Blob Storage, and Azure Data Factory (ADF).
Step-by-Step Guide:
Step 1: AWS S3 Linked Service:
- Navigate to the Azure Data Factory (ADF) portal.
- In the “Author” tab, click on “Connections”.
- Select “New connection”.
- Choose “Amazon S3” from the list of available connectors.
- Enter your AWS account credentials, including Access Key ID and Secret Access Key.
- Test the connection to ensure its successful.
Step 2: Azure Blob Storage Linked Service:
- Navigate to the Azure Data Factory (ADF) portal.
- In the “Author” tab, click on “Connections”.
- Select “New connection”.
- Choose “Azure Blob Storage” from the list of available connectors.
- Select the appropriate Azure Subscription and Storage Account from the dropdown menus.
- Provide authentication details, which may include Storage Account Key or Managed Identity.
- Test the connection to ensure its successful.
Step 3: Creating a Pipeline:
- Creating a New Pipeline.
- Click on the “+” icon in the Author tab and select “Pipeline”.
- Name your pipeline appropriately.
Step 4: Get Metadata Activity:
- Add a “Get Metadata” activity named “Get Folder Metadata”.
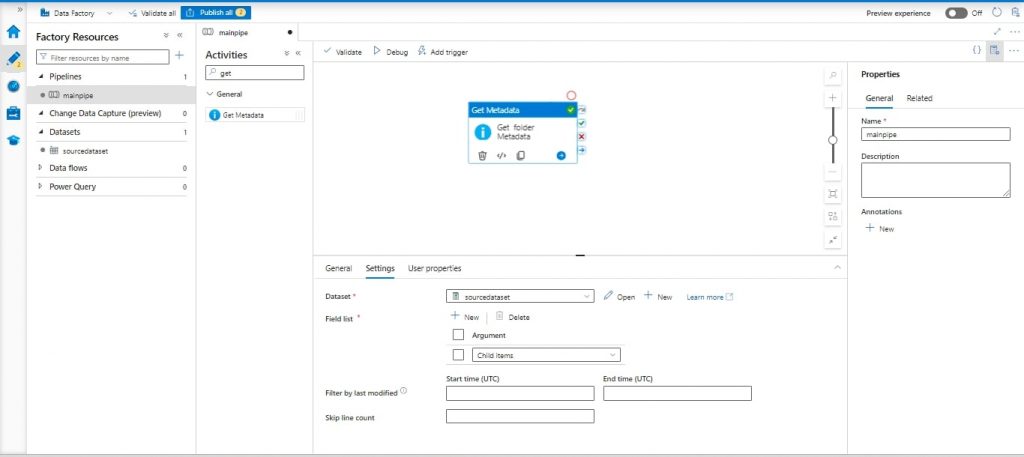
- Configure the source dataset with the AWS S3 Linked Service and specify the bucket path.
- Inside Settings add “Child Items” in field list.
Step 5: Foreach Activity:
- Add a “Foreach” activity named “Loop the Folders” after “Get Folder Metadata”.
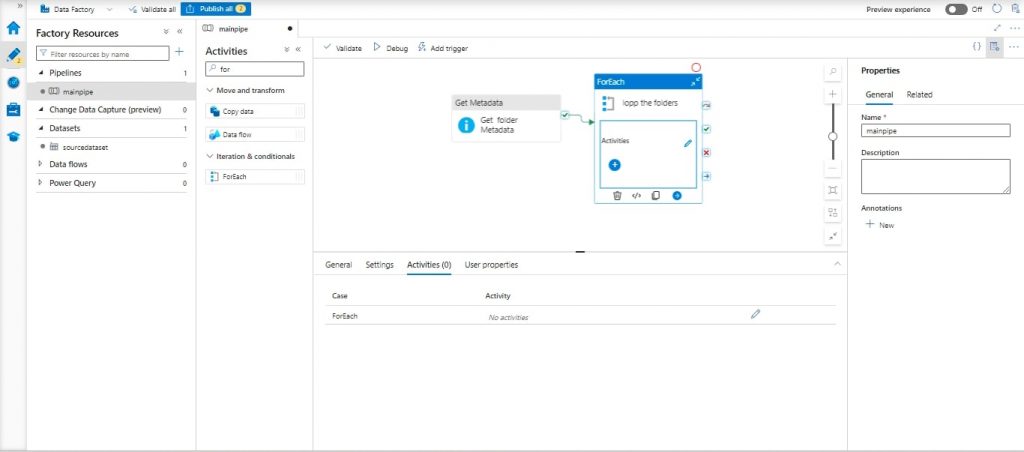
- Set “Sequential”.
- Specify the items for the foreach loop as @activity (‘Get Folder Metadata’). Output. Child Items
Step 6: Execute Pipeline Activity:
- Inside the foreach loop, add “Execute Pipeline” activity named “Execute Child Pipeline”.
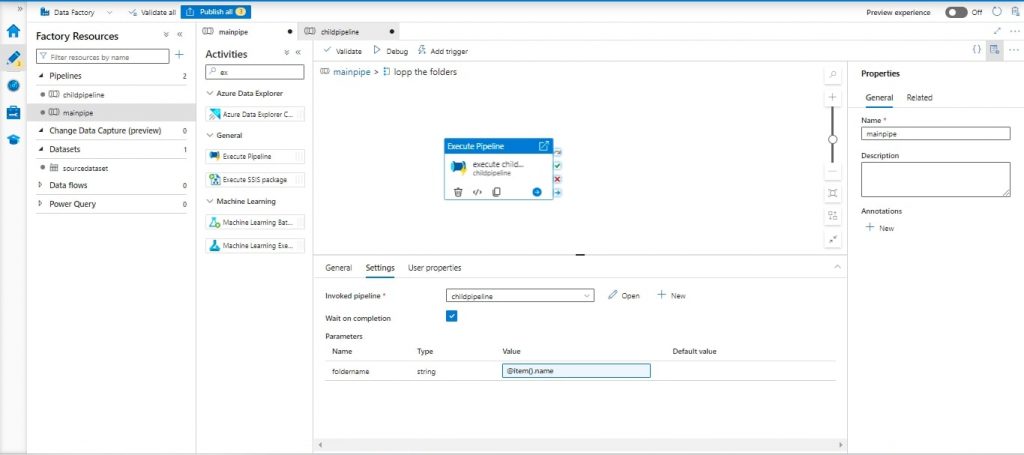
Step 7: Creating Child Pipeline:
- Create a new pipeline named “Child Pipeline” and pass the folder name as a parameter.
- Execute Pipeline Activity and within those settings, there’s a field for specifying a folder name value, which should be defined using the expression “@item().name”.
- Add variables to child pipeline:
- First variable: Filename with default value.
- Second variable: Last modified date with default value.
Step 8: Get Metadata Activity in Child Pipeline:
- Inside the Child Pipeline, add “Get Metadata” activity named “Get File Metadata”.
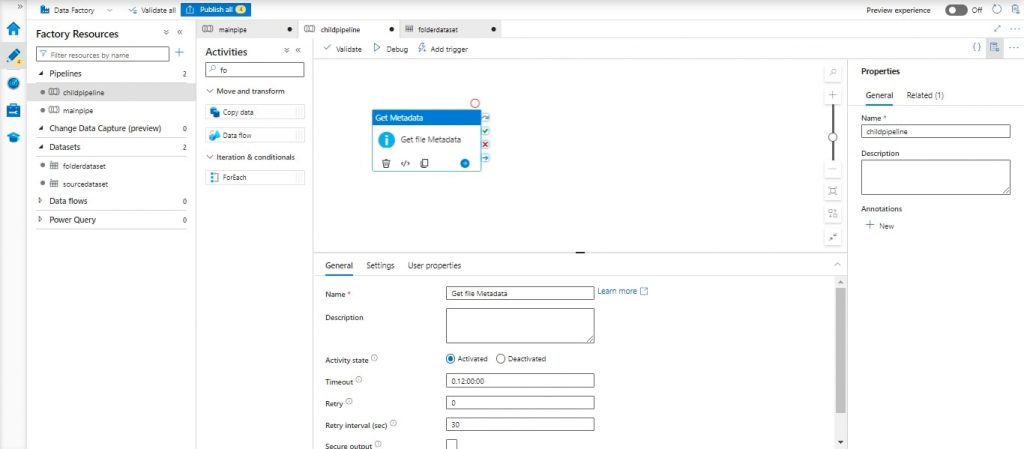
- Configure the source dataset with the AWS S3 Linked Service and specify the folder path using parameters.
- Add parameter folder name in the dataset connection, set the folder name parameter as @dataset (). Folder name.
- In the settings of the “Get File Metadata” here available folder name: @pipeline (). parameters. Folder name.
- Inside Settings add “Child Items” in field list.
Step 9: For Each Activity in Child Pipeline:
- Inside the Child Pipeline, add “Foreach” activity named “Loop the Files” after “Get File Metadata”.
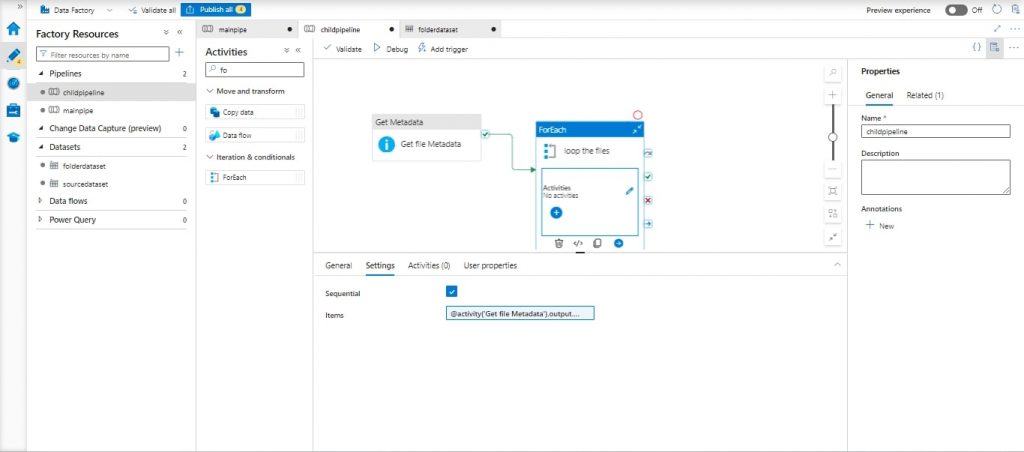
- Set “Sequential”.
- Specify the items for the foreach loop as @ activity (‘Get File Metadata’). Output. Child Items
Step 10: Get Metadata Activity for Each File:
- Inside the foreach loop, add a “Get Metadata” activity named “File Information”.
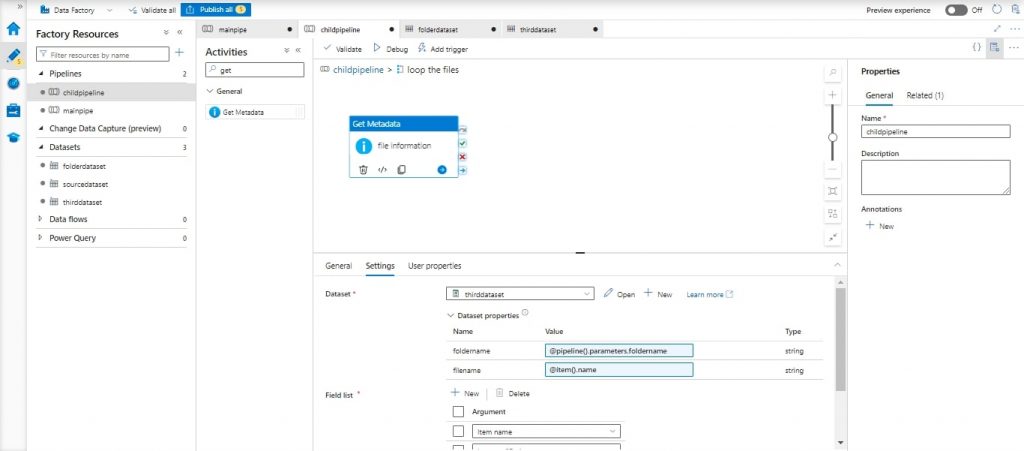
- Configure the dataset with the AWS S3 Linked Service and add 2 parameters folder name and filename in the dataset connection set the folder name parameter as @dataset (). folder name and filename name parameter as @dataset (). folder name.
- In the settings of the “File Information” here available folder name and filename for folder name: @pipeline (). Parameters. Folder name and for filename: @item ().name.
- Inside Settings add ” Item name “and “Last Modified” in field list.
Step 11: Adding If Condition:
- After the above “Get Metadata” activity, add an “If Condition” activity named “Condition Check”.
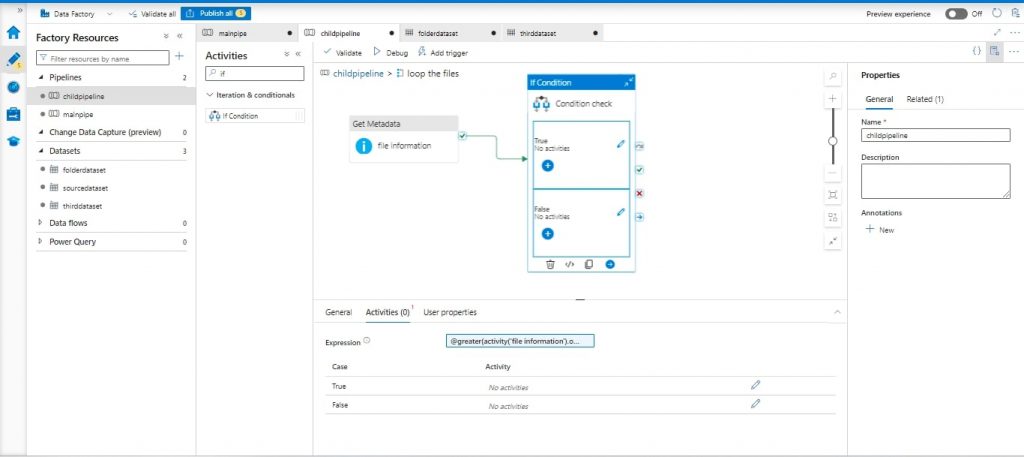
- Configure the condition expression as @greater(activity(‘FileInformation’). Output. Last Modified, variables (‘last Modified date’))
- If the condition is true, inside the “If Condition”, add two “Set Variable” activities:
- First “Set Variable” activity: Name it “Last Modified Value”, set the variable name as “last Modified Date”, and set the value as @activity (‘File Information’). Output. Last Modified
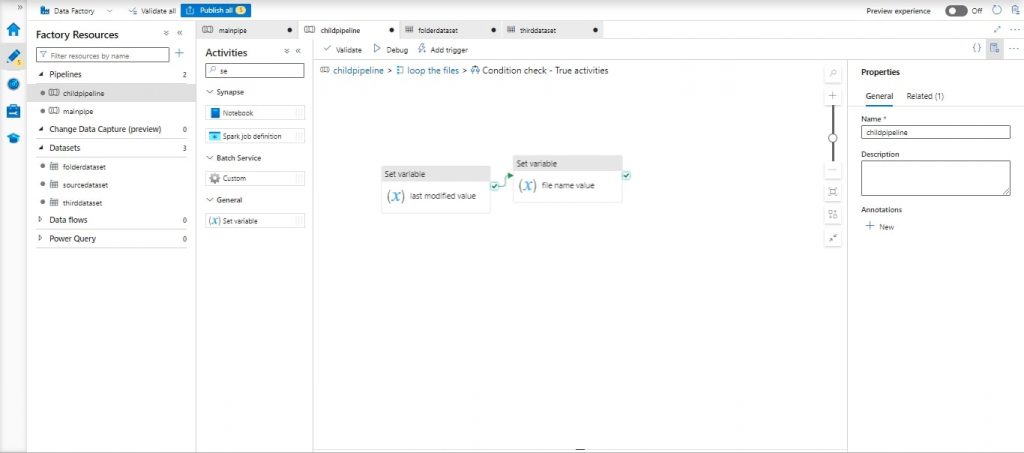
- Second “Set Variable” activity: Name it “Filename Value”, set the variable name as “filename”, and set the value as @activity (‘File Information’). Output. Item Name
Step 12: Adding Copy Data Activity:
- After the foreach loop, add “Copy Data” activity .
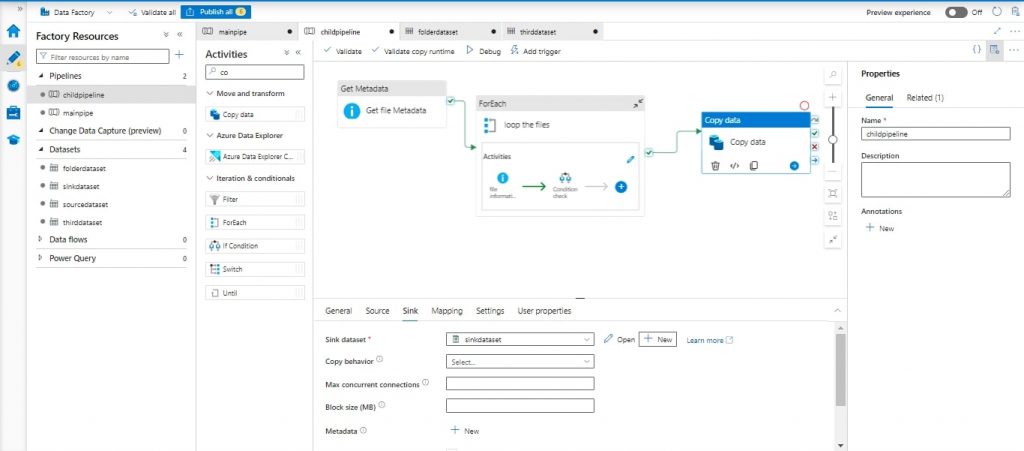
- Configure the source dataset with the AWS S3 Linked Service and add 2 parameters, folder name and filename, in the dataset connection set the folder name parameter as @dataset (). folder name and filename name parameter as @dataset (). folder name.
- Within the ‘File Information’ activity. It highlights the ability to define the folder name using the expression @pipeline().parameters.FolderName and the filename using @variables(‘filename’).
- Configure the sink dataset with the Azure Blob Storage Linked Service and specify the container name.
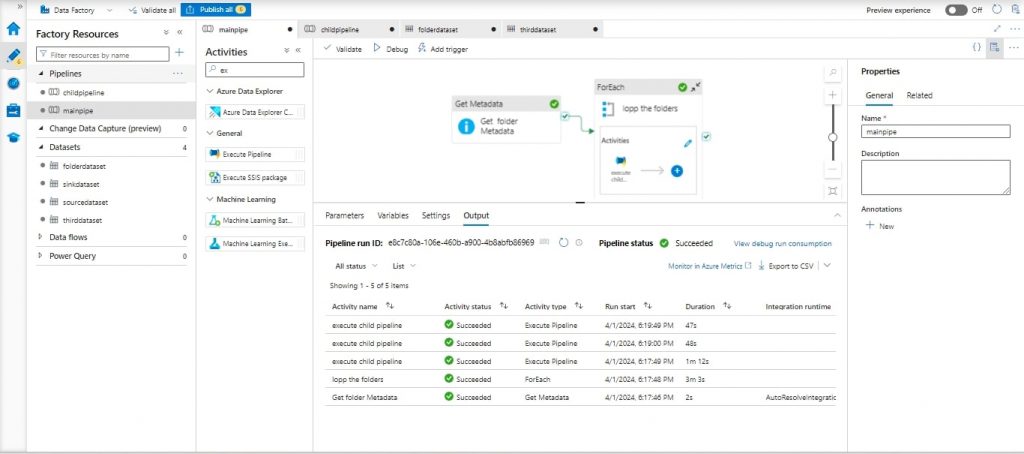
Step 13 Verify Pipeline:
- Once the Pipeline has executed successfully, we can observe the successful completion of all activities.
Conclusion:
To recap, by following the steps outlined in this guide, you’ll be able to set up an Azure Data Factory pipeline to efficiently process and copy the latest uploaded or modified files from multiple folders within an AWS S3 bucket to Azure Blob Storage. This automated process streamlines your data integration workflow, ensuring only relevant files are transferred.
Author Bio:

Vijay Kumar MALLELA
Mobility - Associate Software Engineer
I am an Associate Software Engineer specializing in data engineering at MOURI Tech, with more than one year of experience in SQL. I have good knowledge on Azure Data Factory and a basic understanding of Python programming.
