
Purpose of the article: In This article explains about effectively copy the latest and modified files from multiple folders within in Azure Blob Storage to Microsoft fabric Lakehouse.
Intended Audience: This blog guides users through setting up an Azure Data Factory (ADF) pipeline to efficiently copy the latest and modified files from multiple folders in Azure Blob Storage to Microsoft fabric Lakehouse.
Tools and Technology: Microsoft Fabric (Data Factory, Lakehouse), Azure Services (Azure Blob Storage).
Keywords: Data Integration, Automation Pipeline, Data Migration
Architecture:
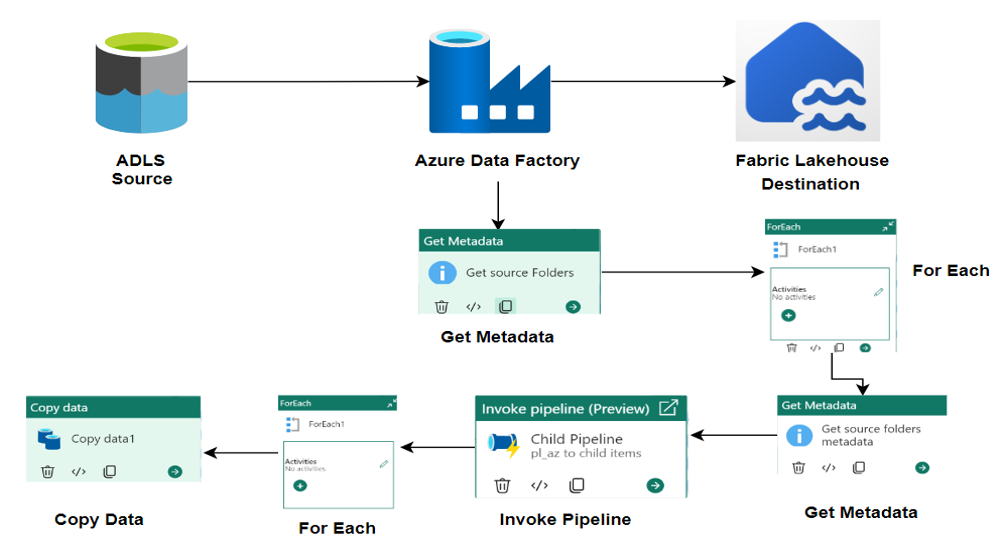
Preparatory Steps: Setting up the Azure Blob Storage, Microsoft Fabric Lakehouse and pipeline. Ensure that the necessary prerequisites are in place, including setting up Azure Blob Storage, Azure Data Factory (ADF) in Microsoft Fabric and Lakehouse.
Step-by-Step Guide:
Step-1: Azure Blob Storage:
- Navigate to the Azure portal.
- Click on the “+” to create a resource, then search for “Storage Account”.
- Select your Azure Subscription (ex. Free trail), create a Resource Group, and provide a unique Storage Account Name.
- Enter your Storage Account details. Click on Review “+” to create.
- Click “Create” to successfully deploy the Storage Account.
- Go to resource, and it will direct you to your Storage Account.
- In the left menu, choose “Data Storage”, then select “Containers”.
- Click on the “+” icon to create a New Container, enter your container name, and then click “Create”.
- Click on the container you created, then click on “+” to add a directory and provide your folder name.
- Click on the folder, then upload your blob files.
Step-2: Creating Microsoft Fabric Lakehouse:
- Navigate to the https://app.fabric.microsoft.com portal.
- In the Fabric environment, on the left side, there is an option for “Workspaces”.
- Select “Workspaces” then click on + “New Workspace” to create a new workspace.
- Enter your workspace name. Workspace will be created successfully.
- Go to your workspace. There is an option “+” New.
- Click on “+” New. Multiple options are available here. Select Lakehouse.
- Give your Lakehouse, a name.
- In Lakehouse It will create semantic model and SQL analytics endpoint by default.
- In the Fabric environment, you will see your created workspace and Lakehouse on the left side.
Step-3: Creating Data Pipeline:
- In the Fabric environment, click on the Microsoft Fabric logo located at the bottom left to reveal a list of components.
- Click on Data Factory to open its page, where multiple options are available.
- Enter your Pipeline name.
- Pipeline created successfully.
- Created pipeline will redirect into your pipeline
Step-4: Get Metadata Activity:
- Add an “Get Metadata” into canvas area. Activity named called “Get Folders Metadata”
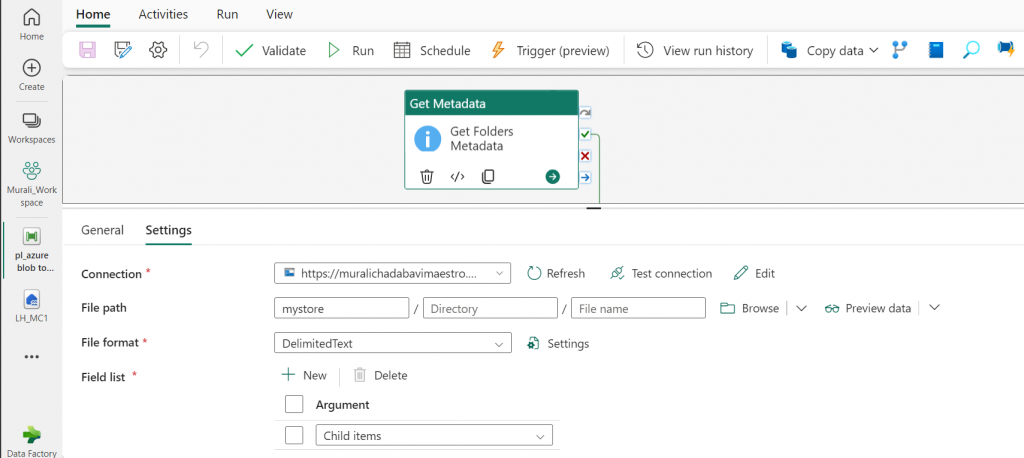
- Configure the source connection Azure Blob Storage to giving the storage account name, connection name and Secret Access Key.
- In the settings, browse your location and specify the root folder in the file path.
- Inside settings, include “Child items” in the field list.
Step-5: Foreach Activity:
- Add “Foreach” Activity named called “Looping the folders” into canvas area.
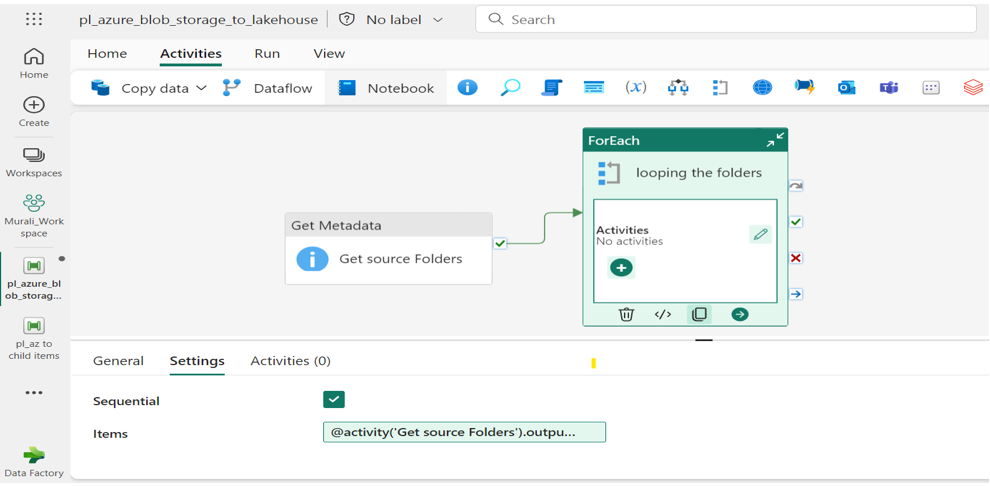
- Enable the Sequential Field inside settings.
- In Items field specify the items for the Foreach loop as @activity (‘Get source Folders’). output. child items.
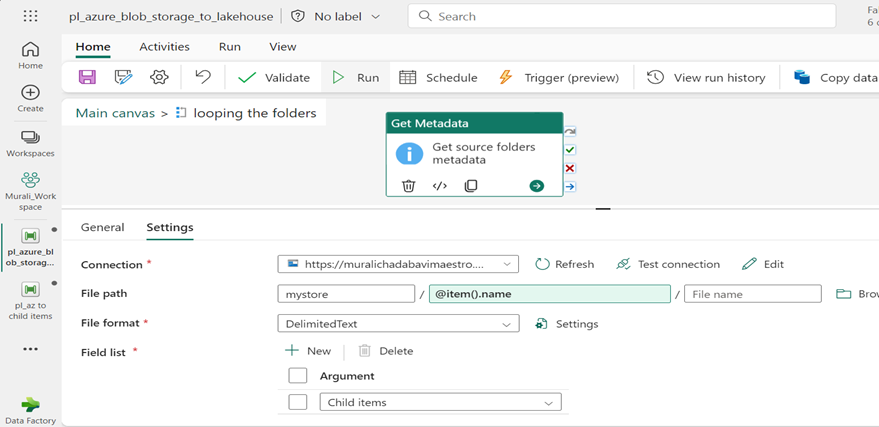
Step-6: Get Metadata Activity:
- Inside Foreach Activities click on pencil icon. Add a “Get metadata”. Activity adds into canvas area.
- Activity Named called “Get Source Folders Metadata”.
- Configure the Source Connection.
- Specify the Root Folder and Directory name add Dynamic Expression @item ().name.
- Include “Child items” in the field list under settings.
Step-7: Invoke Pipeline Activity:
- Within the Foreach loop, add an “Invoke Pipeline” activity and name it “Invoke Child Pipeline”.
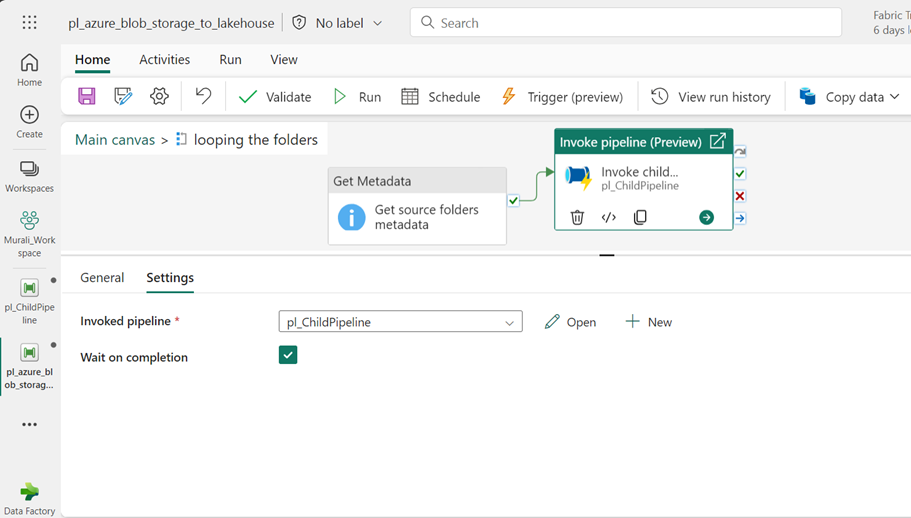
- After that, connect the “Get Metadata” activity to the “Invoke Child Pipeline” activity.
- Use the “Get Metadata” activity to fetch the folder metadata and forward it to the child pipeline.
Step-8: Creating Child Pipeline:
- Inside the settings in Invoked pipeline “+” Click on New option.
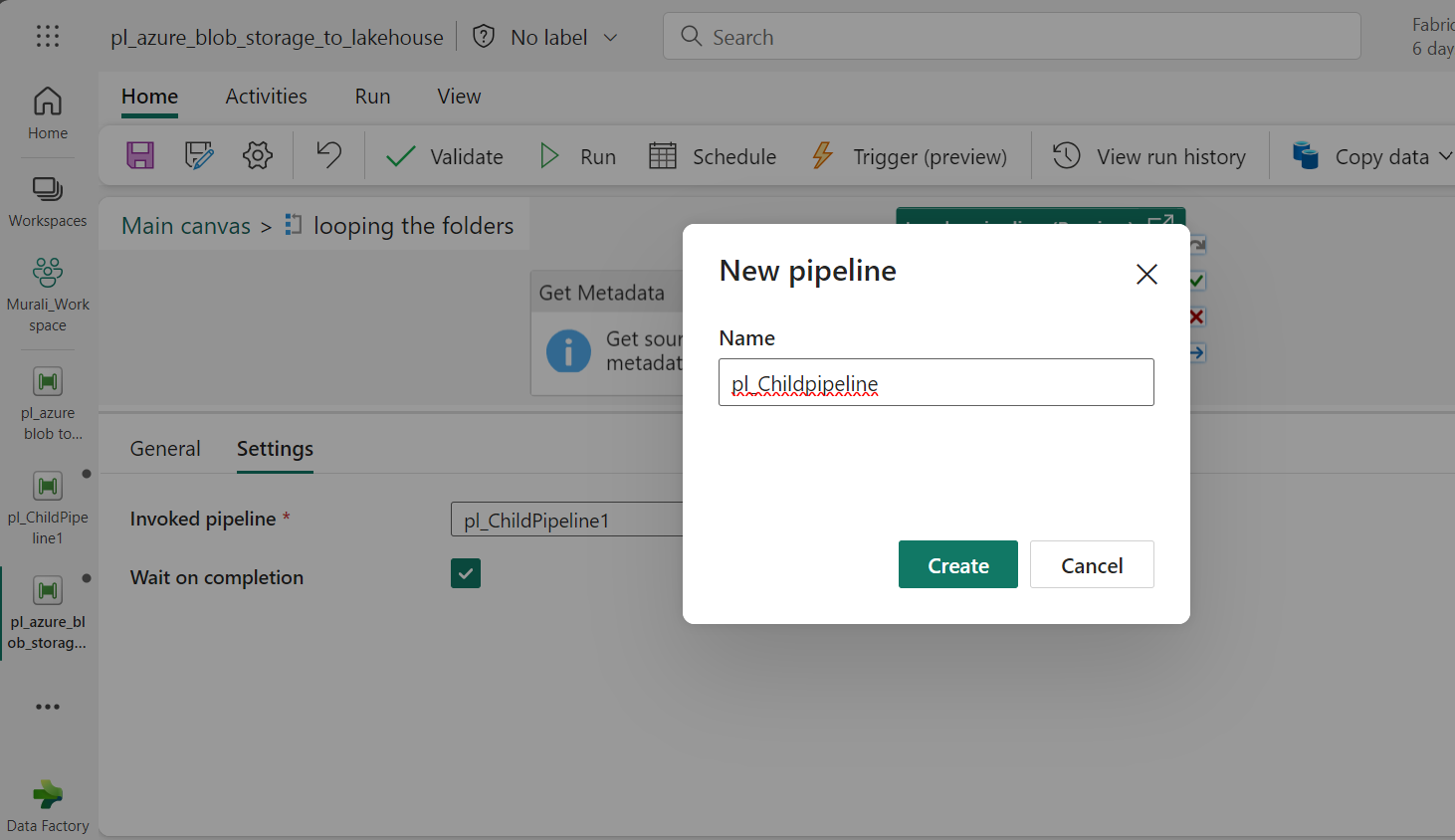
- Enter the required name, then click “Create”, you will then be redirected to your child pipeline.
Step-9: Foreach Activity in Child Pipeline:
- Inside the child pipeline, add a “Foreach Activity” named “loop the folders”
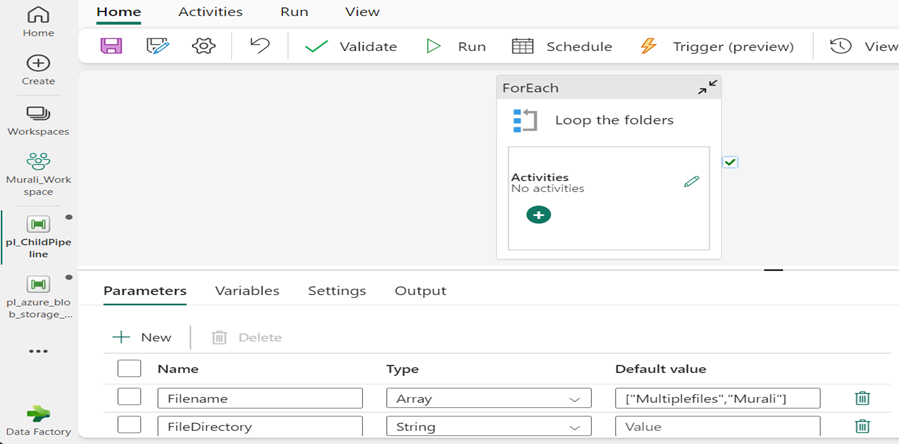
- Add parameters @Filename and @Filedirectory to the child pipeline, setting a default value for @Filename.
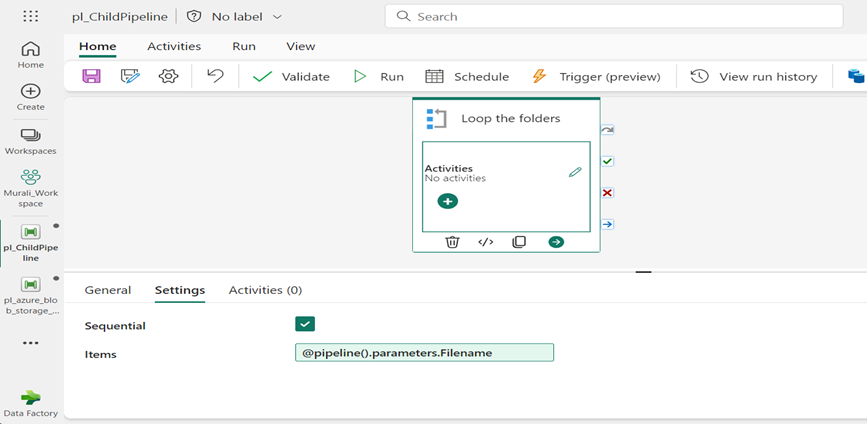
- In the same “Foreach Activity”, enable the “Sequential” field inside the settings.
- Specify the items for the Foreach loop as @Pipeline (). Parameters. Filename.
Step-10: Copy Data Activity in Child Pipeline:
- In the “Foreach activity”, insert a “Copy Data” activity and label it “Copying the data”.
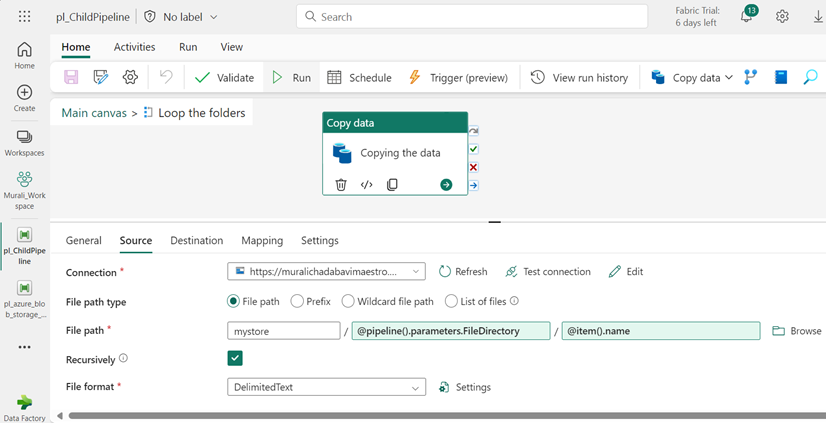
- Connect to the source by selecting the file path. Once there, type within the source connection.
- Specify the root folder in file path, passing the child pipeline parameter in directory field
@pipeline (). parameters. file directory and to giving the file name as @item.name.
- Select “Delimited text” in File format.
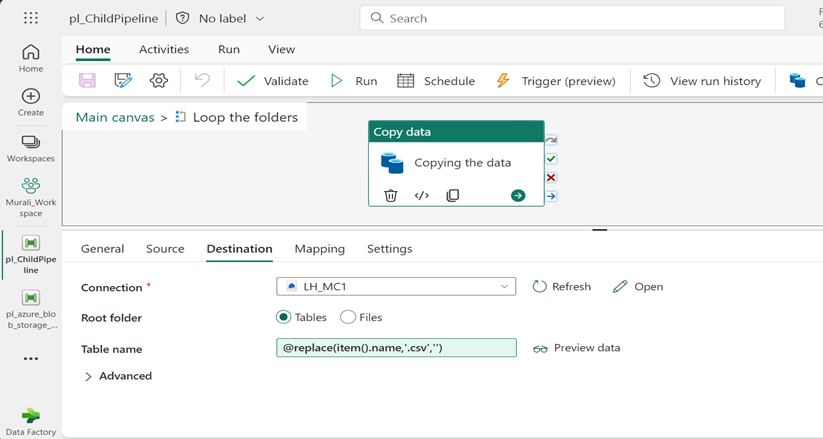
- Inside Destination Field, give your Lakehouse, a name which you have created like @LH_MC1.
- Specify the Root Folder select Tables.
- Give table name as Dynamic content Expression @replace (item ().name, ‘.csv’, ‘‘).
Step-11: Invoke(Execute) Main Pipeline:
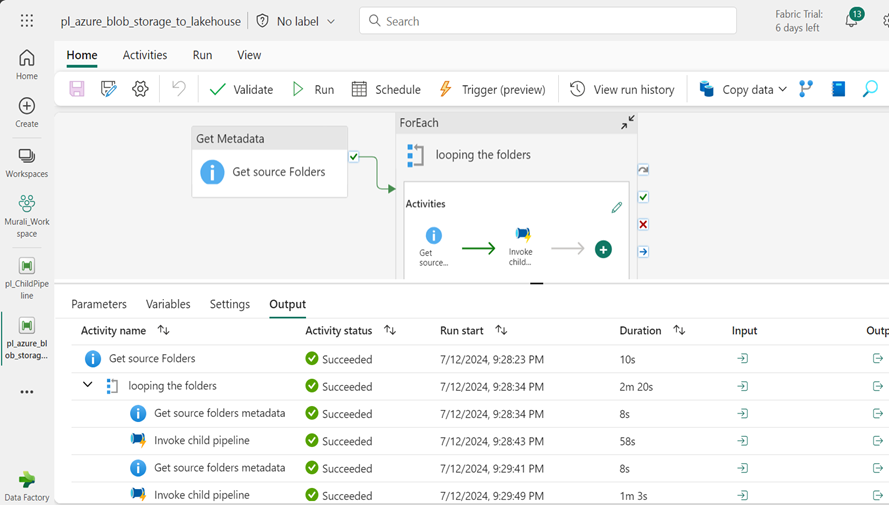
- Pipeline Executed Successfully. We observe all activities have been completed.
Conclusion: From copying the latest and modified files from Azure Blob Storage to Microsoft Fabric Lakehouse can Significantly enhance the data management and analytics capabilities. By efficiently automating this process, you ensure that Lakehouse is always up to date with the recent most data, which is reducing the latency and improving the reliability of your data- driven decisions. The seamless Integration between Azure Blob Storage to Microsoft Fabric Lakehouse not only helps data ingestion but also enhances performance and scalability, making it an optimal solution for managing large volumes of data across multiple folders. This streamlined approach allows for better resource utilization and more efficient data workflows, ultimately leading to faster and more informed business Insights.
Author Bio:

Murali CHADABAVI
Associate Software Engineer - Data Engineering- Analytics
I’m Murali CHADABAVI, and I’ve been with MOURI Tech for more than one year as Associate Software Engineer in Data Engineering. I have a Good Knowledge on SQL, Azure Data Factory and a basic understanding of Python coding language.
