
Purpose of the Article: In this blog, we have explained how we can process spatial data using AWS services.
Intended Audience: This POC/blog will help developers working on geometry data.
Tools and Technology: AWS services
Keywords: Loading a shapefile into Amazon Redshift
Objective
- Discuss how we can handle spatial data using Redshift & lambda
- An example to show the Handling of spatial data.
Spatial Data Introduction
A typical example of spatial data can be a road map. A road map consists of 2-D object like lines, points, and polygons that can represent cities, roads, and states. Thus, a road map is a visualization of geographic information.
The geometric location and attribute information of geographic features in a vector format can be stored in a shapefile.
Processing can be challenging, but the data capturing can be fully automated by using AWS .
Spatial Data Processing Workflows
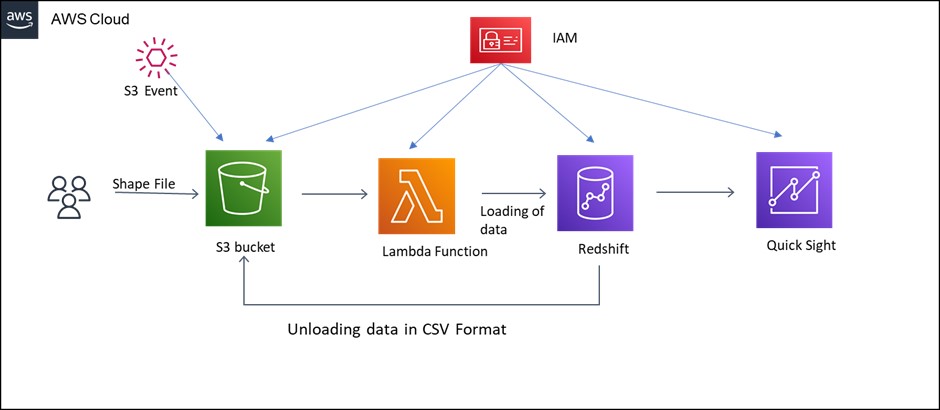
In this use case, we have the processing of shapefile (contains spatial objects) using lambda function and to load data in Redshift and unload those data from Redshift to S3 in CSV format, then pushing Redshift data to quick sight for building dashboard for analysis.
- Data is pushed to Redshift and unloaded to S3 in CSV format using python code in Lambda function.
- An IAM role is created with all the required policies for allowing access between the services used.
- Created S3 event notification for S3 bucket.
- The Lambda function is triggered by the S3 event configured.
- Whenever we upload the Shapefile file into S3, the S3 event will trigger Lambda Function.
- Created Quick sight with necessary configurations and added redshift permission.
- Created Dataset with source as Redshift and Configured redshift connection.
- Choose the direct query option, and you can provide SQL script.
- Created analysis with fetched data and published Dashboard.
- The Dashboard can be refreshed, which allows the user to monitor the current data reports.
AWS Service Used
- S3: It is used for storing/ retrieving Shapefile
- Lambda Function: Used to copy shapefile from S3 to Redshift
- Redshift: Store data and analyze it
- IAM: It provides fine-grained access control across all of AWS
- Quick Sight: It is used to create a dashboard using redshift data and visualize data in graphical form
ARCHITECTURE
Steps to create Lambda Function
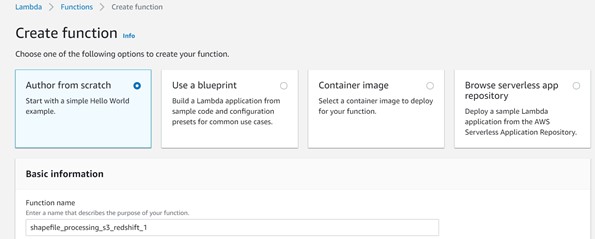
Step 1: Go to Lambda Function in Aws Console and click to create Function.

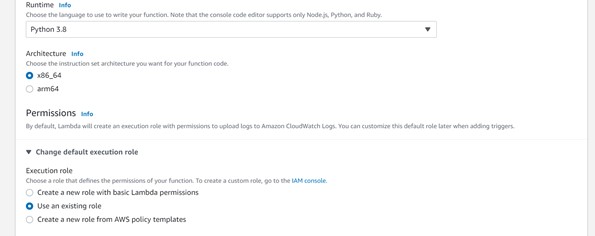
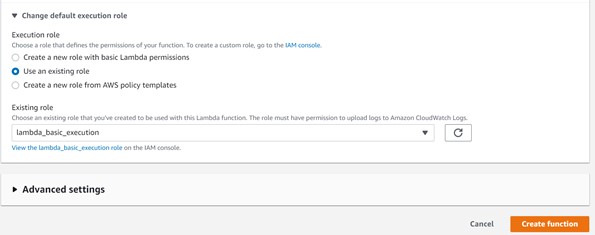
Step 2: Provide basic information like lambda function name, Runtime, execution role, and then click to create Function as shown below.
Step 3: Create a package with the required module and code and then upload the same into the lambda function.
File present in a local system:

Zipped those files
![]()
Upload zip folder in lambda function as shown below: –

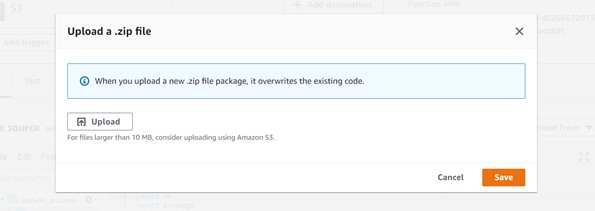
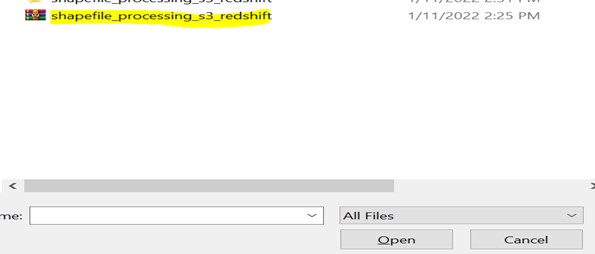
Step 4: The Package has been uploaded, and we can verify the code source as shown below.
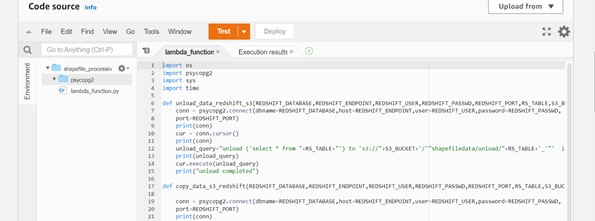
Output: –
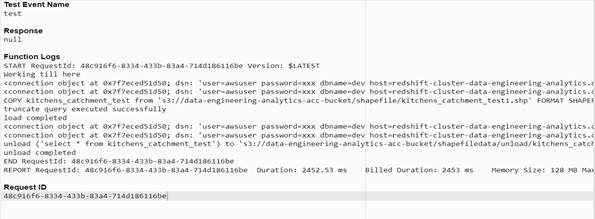
Steps to Create S3 events
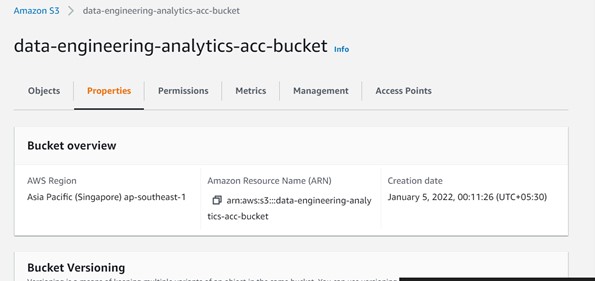
Step 1: – Go to the S3 bucket and choose the bucket where you need to configure the event and then go to properties as shown below.
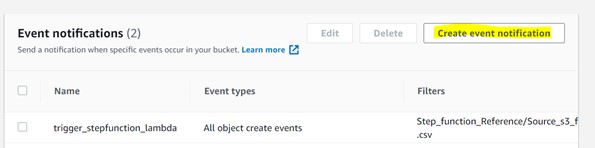
Step 2: – Choose to create an event notification.
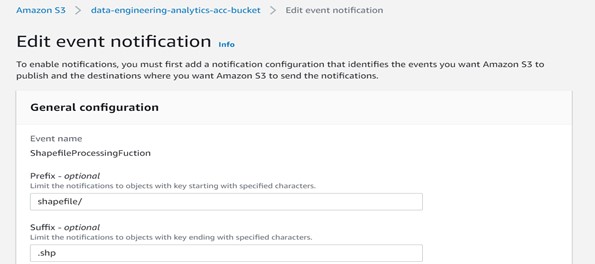
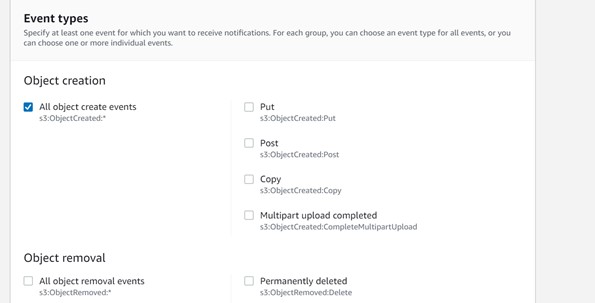
Step 3: Provide Event name, prefix, suffix, event type, and destination details below.
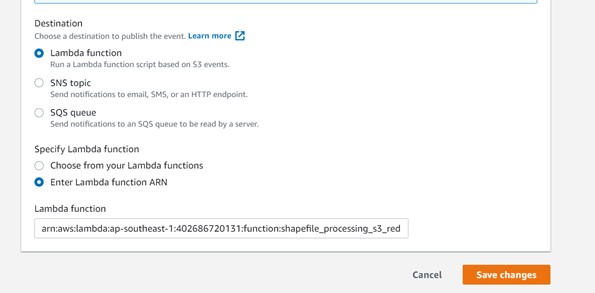
Step 4: – Event notification has been created, as shown below.
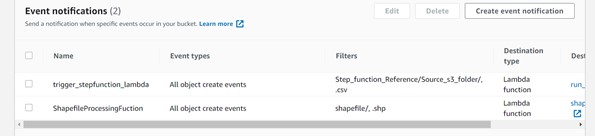
Note: Shape file should be set of 3 files i.e. .shp, .shx, and .dbf. The .shp, .shx, and .dbf files must share the same Amazon S3 prefix and file name.
Steps to Create Quick Sight
Step 1: Go to Quick Sight and create a new dataset.
Step 2: Choose your source.

Step 3: Configure data source information as shown below.
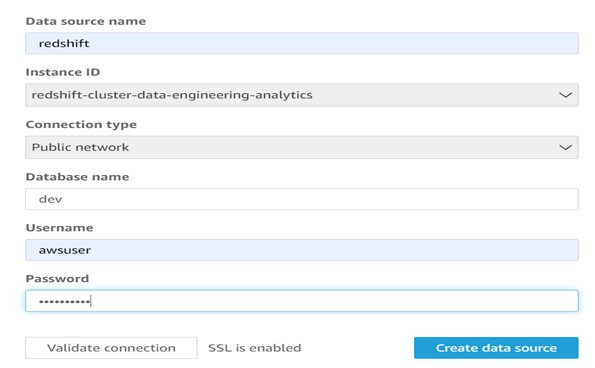
Step 4: Select the use custom SQL option.
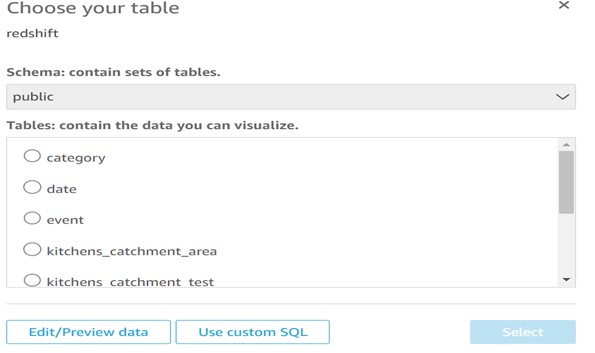
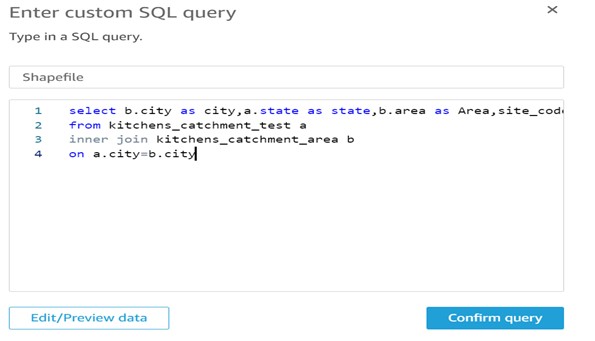
Step 5: Provide SQL query as per your requirement and confirm it.
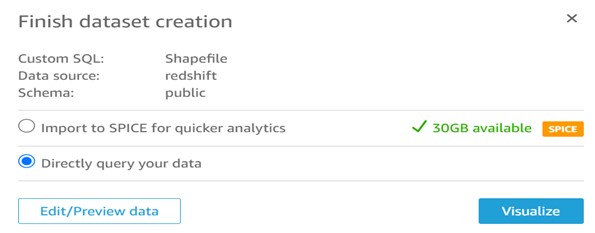
Step 6: Choose Direct query your data and click on visualize.
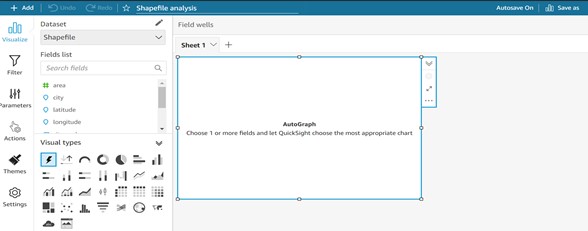
Step 7: Create Dashboard as shown below.
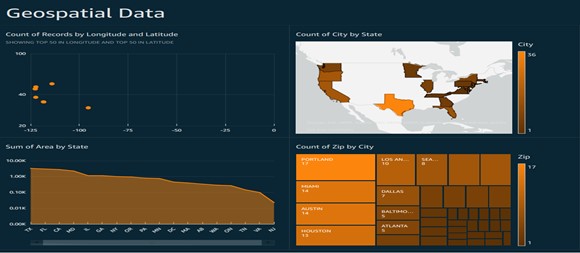
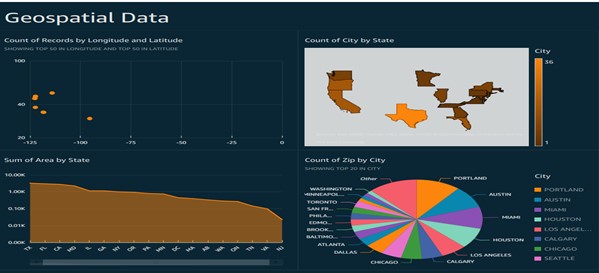
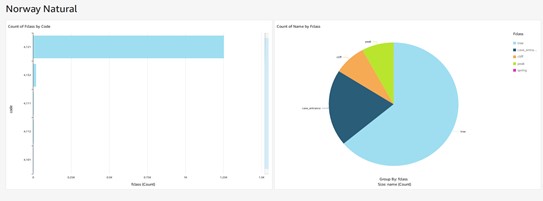
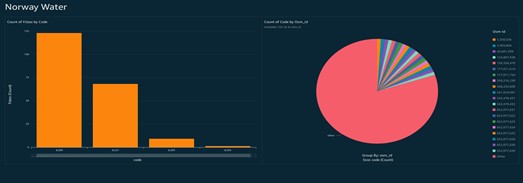
Conclusion: It is now possible to read and write spatial data using the shapefile format, capturing, and processing shapefile using AWS lambda function, Simple Storage Service (S3), Redshift, Access Management (IAM), and Quick sight.

